Compute shader 3: кэши CPU и GPU

Похоже, у меня получился небольшой сериал про Compute shader, и на этой неделе я собираюсь закончить его, обсудив вычислительные блоки и кэши. Настоятельно рекомендую сначала ознакомиться с первой и второй частью, потому что я часто буду на них ссылаться. Кэши или вычислительные блоки, с чего бы начать? Возьмем сначала блоки.
Исполнительные порты
Если вы знакомы с современным дизайном CPU, вы знаете, что он не является скалярным устройством, обрабатывающим по одной инструкции за раз. В современной архитектуре наподобие Zen имеется 10 исполнительных портов. Часть из них целочисленные, а часть — для операций с плавающей точкой:
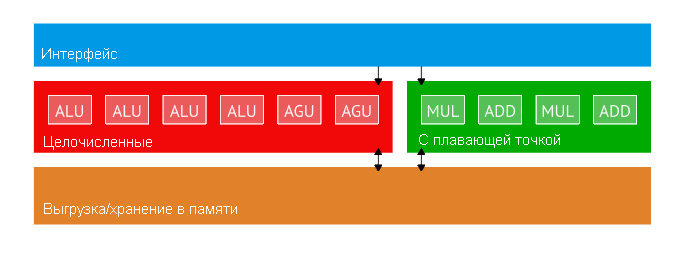
У Zen есть десять вычислительных блоков: для операций с плавающей точкой и целочисленных.
GPU также получают выгоду от наличия множества исполнительных портов, но не в том же смысле, что CPU. На процессоре инструкции выполняются не по порядку, а некоторые из них — спекулятивно. Такое невозможно для GPU. Для всего “железа” с выполнением не по порядку и переименованием регистров требуется еще больше регистров, а графические процессоры уже имеют тысячи (например, у Vega10 на кристалле 16 Мбайт регистров). Не говоря уже о том, что спекулятивное исполнение увеличивает потребление энергии и это уже сильно ограничивающий фактор для графических процессоров, работающих с очень большими рабочими нагрузками. Наконец, программы GPU не выглядят так, как программы для процессоров. Порядок, спекуляции, предварительная выборка и т.д. хорош, если вы выполняете GCC, но не для старых добрых пиксельных шейдеров.
Как говорилось, очень разумно давать запросы к памяти в то время, пока SIMD заняты обработкой данных или по порядку выполняет скалярные инструкции. Так как мы можем получить эти выгоды не нарушая порядка? GPU превосходит CPU в том, что выполняет очень много работы в полете. Так же, как мы пользовались этой особенностью для сокрытия латентности, мы можем взять ее для планирования. В CPU мы смотрим вперед одного потока команд и пытаемся найти независимые команды. В GPU у нас есть тысячи независимых потоков команд. Самый простой способ получить параллелизм на уровне инструкций — просто иметь разные блоки для разных типов команд и выдавать инструкции соответственно. Оказывается, именно так построен GCN, с несколькими портами выполнения за такт:
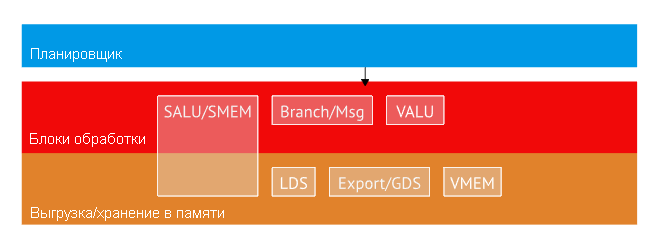
GCN имеет несколько портов исполнения на один такт: скалярный ALU/скалярная память, ветки/сообщения, Векторный ALU, LDS, экспорт/GDS и векторная память.
Всего есть шесть различных портов исполнения, и диспетчер может отправлять по одной инструкции в такт максимум на пять из них. Существуют особые инструкции, передаваемые диспетчером непосредственно (например, NOP отправлять в блок совершенно бесполезно). На каждом такте диспетчер просматривает активные вейвы и на следующую готовую к исполнению инструкцию. К примеру, давайте предположим, что для выполнения у нас есть следующий код:
v_add_f32 r0, r1, r2 s_cmp_eq_i32 s1, s2
Если готовы два вейва, диспетчер отправит первый v_add в первый SIMD. В следующем такте он получит s_cmp из первого вейва и v_add со второго. Таким способом скалярные команды перекрывают выполнение векторных, и мы получаем параллелизацию на уровне инструкций без забеганий вперед и дорогих неупорядоченных вычислений.
Давайте рассмотрим более сложный пример, в котором несколько вейвфронтов выполняют скалярные и векторные команды, а также запросы к памяти:
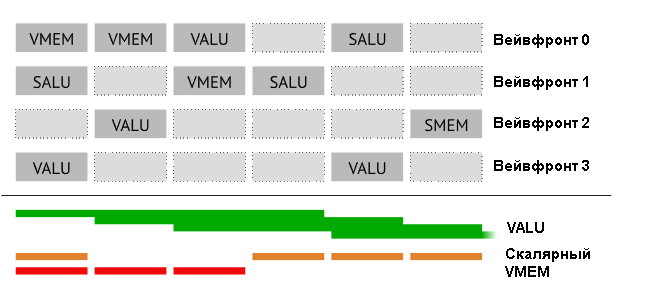
В верхней части показано, как распланированы вейвфронты (такты идут слева направо). В первом такте три независимые команды передаются трем блокам. Не забывайте, что VALU работает четыре такта. В нижней части показывается, насколько сильно загружены блоки. Поскольку команды в VALU исполняются в течение четырех тактов, все четыре блока SIMD становятся задействованными очень быстро. Добротная смесь команд гарантирует, что будут заняты все блоки.
Перед там, как закончить, надо рассмотреть еще обработку загрузки и хранение. В CPU все прозрачно, так что вы можете написать последовательность следующим образом:
mov rcx,QWORD PTR [rsp+0x8] add rdx, rcx
Это работает, потому что проследив за этой информацией CPU “знает”, что загрузка должна завершить до того, как начнется выполнение операции. В GCN ISA для ожидания пока не завершится несколько загрузок используется специальная команда s_waitcnt. Это не просто ожидание всего что угодно, команда позволяет передать по конвейеру одновременно несколько загрузок и затем употребить их одну за другой. Соответствующие действия у GCN ISA будут выглядеть примерно так:
s_buffer_load_dword s0, s[12:15], 0x0 ; загрузить один dword s_waitcnt lgkmcnt(0) ; подождать пока предыдущая загрузка завершится v_add r0, s0, r1 ; использовать загруженные данные
Я думаю, было бы правильно считать (GCN) GPU как CPU, выполняющий по четыре потока на ядро (вычислительный блок), и каждый поток может выполнять скалярные, векторные и иные команды. Это нормально, а разработчики сделали компромисс между сложностью программного и аппаратного обеспечения. Вместо сложных аппаратных средств GPU нужно солидное программное обеспечение для параллельных вычислений. Не только чтобы спрятать латентность, но и для лучшей загрузки всех вычислительных блоков. Вместо “автоматического” слежения все это требует от компилятора добавлять дополнительные команды, а приложение должно обеспечить достаточную параллельность. Но вместе с тем мы получаем огромную пропускную способность и тысячи вычислительных блоков. Вот хороший пример того, как особенности исполняемого кода могут повлиять на дизайн аппаратных средств.
Кэши
Если говорить о том, как программные средства влияют на аппаратные, нельзя не упомянуть о кэшах. Кэши GPU это еще один — и последний в этой серии — пример того, как графический процессор сконструирован специально для большого объема параллельной работы, и на какие компромиссы для этого пришлось пойти конструкторам. Мы также обнаружим, что CPU на самом деле следует по пути, аналогичному GPU!
CPU
Давайте сначала посмотрим, как выглядят современные процессоры, например 32-ядерный серверный процессор архитектуры Zen:

Современный серверный процессор на архитектуре Zen. Конфигурация содержит четыре матрицы, в каждой из которых по два комплекса ядер. В каждом комплексе ядер есть 8 MiB кэша L3, 4 кэша L2 по 512 KiB каждый, 4 кэша L1 по 32 KiB каждый и 4 командных кэша по 64 KiB каждый. Это очень много кэша — только на L3 в общей сложности приходится 64 MiB!
Перед нами огромный CPU, и что интересно: для высокопроизводительного кода имеет значение топология. Общий кэш L3 для двух ядер явно позволяет обмениваться данными напрямую, а обращение в другой L3 уже требует пройти некоторый путь, не говоря о том, что это перемещение через матрицу. Такова природа, поскольку чем больше становятся чипы, тем больше становится площадь матрицы кристалла, и перемещение информации на большое расстояние становится дороже энергетически и по времени. Волшебного средства для преодоления данной проблемы нет — таковы законы физики — и за исключением того, что каждое ядро оплачивает наихудшую задержку для всех остальных, всегда будет какая-то еще.
Что это значит для разработчика приложений? Это значит, что выполнение всех команд в приложении должно быть “близко”. Обычно за этим следит планировщик ОС. По умолчанию все кэши когерентны друг с другом. То есть когда ядро в левом верхнем углу пишет что-либо в память, это видит ядро в нижнем правом углу. Для этого были разработаны различные протоколы. Суть в том, что любое ядро может записывать в память, и любое другое ядро увидит новые данные по умолчанию. Никакой дополнительной работы от приложения — но вы можете себе представить, что обмен данными между ядрами потребовал бы очень много работы.
GPU
Итак, в GPU проходит намного больше параллельных процессов, чем в CPU. Графический процессор Vega10, технически говоря, является 64-ядерным CPU в похожей иерархией кэша. Давайте посмотрим на него:
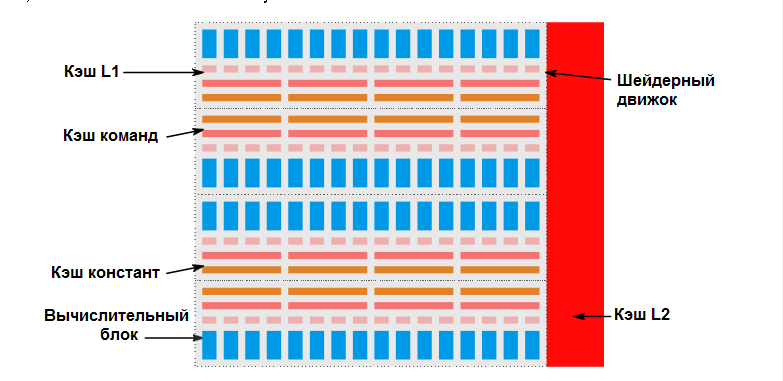
Vega10 GPU, состоящий из 4 шейдерных движков. Каждый шейдерный движок содержит 16 вычислительных блоков. Вычислительный блок имеет 16 KiB кэша L1, четыре вычислительных блока имеют общий 32 KiB командный кэш и 16 KiB скалярного (константого) кэша. Все шейдерные движки соединены с 4 MiB кэшем L2.
Размеры абсолютно иные, но смутное подобие имеется. Если достаточно поднапрячься, можно представить, что перед нами 64-ядерный процессор на одном кристалле. Очевидно, дьявол снова скрывается в деталях, потому что CPU имеют согласованность по умолчанию, а GPU работают в совершенно другом режиме. Его устройство оптимизировано под выполнение многих независимых задач, поэтому давайте подумаем, как это повлияет на кэш. Учитывая, что каждый рабочий элемент является независимым, мы можем предположить, что каждое ядро работает с собственными данными, и между ядрами практически нет общего доступа. Как мы можем оптимизировать оборудование для этого? Прежде всего, мы избавимся от согласованности по умолчанию. Если ядро A что-то пишет и хочет, чтобы ядро B его увидело, теперь это ответственность разработчика. Предполагается, что такое редко необходимо, так как потребуется две синхронизации: одна в памяти (нам нужно как-то стереть данные из кэша), а вторая — чтобы второе ядро как-то обрабатывало те же данные. Как мы узнали, графические процессоры обычно не особо любят соблюдать порядок выполнения, и это напрямую влияет на обработку кеша. Поскольку синхронизация легла на разработчика, GPU для поддержки могут создавать барьеры памяти.
А еще кэши не управляют собой. В CPU все, как правило, работает только в рамках одного процесса, но на графическом процессоре скрытые и недействительные кэши являются очень явной операцией. Если вы закончите один вычислительный шейдер и хотите начать следующий, GPU обычно сбрасывает и аннулирует все локальные кеши вычислительного блока, чтобы все работы были гарантированно завершены и следующая отправка увидела данные. Из-за этого крайне важно сохранить данные в L2: очистка кэшей L1 происходит очень часто, но дешево, потому что они маленькие. Сравните это с процессором, где L2 одного ядра вдвое меньше всех вместе взятых кэшей L1 в GPU!
Также интересные общие кэши. В случае CPU общие данные есть только в L3. В GPU, где одна программа будет выполняться многими вычислительными блоками, кэш инструкций является общим для них. Это означает, что в идеале мы хотим отправить одну и ту же программу в группы из четырех вычислительных блоков, а не полностью случайно по GPU. Точно так же мы предполагаем, что одни и те же константы загружаются по всем вэйвам, выполняющим одну программу, что отражено в наличии кэшей констант (скалярных кэшей). Практически, те доступны только для чтения (исключая атомарные инструкции), и означит, что их не нужно очищать (изменять данные), но все равно надо объявлять недействительными между отправлениями.
Вы можете задаться вопросом: как при таких настройках по умолчанию добиться согласованности кэшей? Разумеется, способ есть, поскольку GLSL, например, имеет когерентный модификатор. Рад, что вы спросили — решение довольно простое. Все вычислительные блоки разделяют один L2, поэтому, если надо обеспечить согласованность, мы можем просто обойти L1. Если вы посмотрите на GCN GCA, там есть бит GLC, в котором говорится: «Принудительный обход кэша L1». Записывая в L2 и всегда читая из L2, мы можем создать видимость связных кэшей без какого-либо протокола согласованности. Все за счет простого игнорирования (крошечного) L1 — опять-таки компромисса, который имеет смысл для графических процессоров.
Наконец, давайте поговорим о размерах еще раз. По сравнению с процессором, кеши GPU крошечные, так почему они все-таки есть? На процессоре кэши нужны для повторного использования, и поскольку в регистрах нельзя хранить почти никаких данных, эти кэши большие. С другой стороны, код для CPU имеет тенденцию читать память повсюду, но обычно не читает большие фрагменты близлежащих данных. Представьте базу данных — вероятность того, что вы собираетесь прочитать несколько записей подряд, довольно низкая.
Графические процессоры должны решать другую проблему. Тонны потоков в полете, все они хотят либо передавать данные, либо получать доступ к данным пространственно-согласованным способом (например, к текстурам). Для этого варианта использования в реальности надо использовать кеш, который поможет комбинировать чтения / записи и хранить данные достаточно долго, чтобы переместить их в регистры. Например, вы поэлементно загружаете 4 компонентный вектор. В идеале нужно, чтобы четыре компонента были «кэшированы» пока загрузка не закончится. Крошечный кеш идеально подходит для этого — он поддерживает кэширование линии до тех пор, пока ее не употребят, и вероятность того, что вы попадете в тот кэш снова, очень мала, так как потоки обрабатывают тонны (независимых) данных. В данной серии статей это был последний пример, как исполняемый код и его предполагаемое использование сделали GPU очень отличным от CPU.
Заключение
Вот и все, ребята! Надеюсь, вам понравилась серия, и вы заметили, что CPU и GPU оба многоядерные, но каждый специально разработан и настроен для разных вариантов использования. Другая интересная вещь — это то, как модель программирования повлияла на аппаратный дизайн и наоборот — и как мы находимся на пути к конвергенции. Код современного GPU, как правило, отлично работает на современных процессорах. Он достаточно хорошо написан, чтобы использовать преимущества многих ядер, может обрабатывать неравномерный доступ к памяти и легко справляться с малыми гарантиями попадания в кэш. Куда мы направляемся? Я не знаю, но знания о вычислительных шейдерах и моделях исполнения GPU помогут подготовиться к тому, что впереди!
