Compute Shaders: введение в вычислительные шейдеры

Пару месяцев назад я отправился в Мюнхенский GameCamp. Это баркемп, где каждый может предложить тему для обсуждения, а затем в ходе быстрого голосования решают, какую тему принять. Я предлагал то одно, то другое. Потом один разработчик сказал, что я, вероятно, хотел бы дать материал о вычислительных шейдерах. Итак, я вошел, не надеясь привлечь много сторонников. В итоге оказался в переполненной комнате, где четверть участников примерно час болтала про вычислительные шейдеры. Основным из вопросов оказался: «Где я могу почитать об этом?». И я не мог дать однозначно хороший вводный материал (есть «Путешествие по графическому конвейеру», но он уже довольно старый.)
Аппаратные средства
Чтобы понять, откуда появились вычислительные шейдеры, мы должны взглянуть на эволюцию аппаратных средств. Еще в старые времена, перед шейдерами, обработка геометрии и текстурирование разделились. Например, карта Voodoo² имела один растеризатор и два блока текстурирования, разделяя рабочую нагрузку между ними. Эта тема продолжалась долгое время, даже после введения шейдеров. До GeForce 7 и Radeon X1950 у графических процессоров были отдельные вершинные и пиксельные шейдеры. Шейдеры обычно имели сходные возможности с точки зрения того, что они могли вычислить (в конце концов, сложение и умножение составляют основную часть работы на графическом процессоре), но доступ к памяти сильно различался. Например, в течение длительного времени вершинные шейдеры не могли иметь доступ к текстурам. В то время разделение имело смысл. Сцены состояли из нескольких полигонов, охватывающих множество пикселей, поэтому наличие меньшей мощности вершинного шейдера обычно не приводило к узкому месту. Уменьшение функциональности вершинных шейдеров позволяло лучше их оптимизировать и делать быстрее.
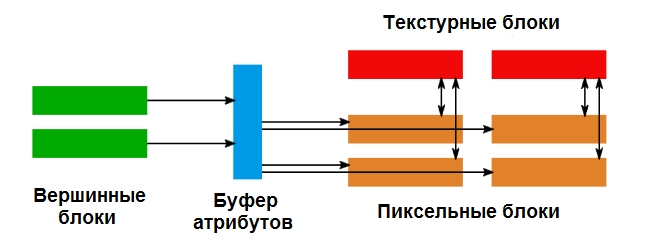
Основной конвейер GPU с отдельными вершинными и пиксельными блоками. Блоки вершин записывают обработанные вершины в буфер атрибутов, пиксельные блоки потребляют его, а также получают доступ к памяти через текстурные блоки.
Однако фиксированное распределение также не дает сбалансированную нагрузку на ресурсы. По мере развития игр иногда требовалась больше мощности для обработки вершин, например, при рендеринге плотной геометрии деревьев, в то время как в других играх использовались новые модели программирования шейдеров для более сложных пиксельных. Это было также время, когда началось программирование GPGPU. То есть программисты пытались решать на графических процессорах численные задачи. В конце концов стало ясно, что фиксированное разделение недостаточно хорошо работает.
В конце 2006 — начале 2007 года, с выпуском GeForce 8800 GTX и Radeon HD 2800 началась эра «унифицированных шейдеров» (технически говоря, первым был XBox 360). Прошли времена отдельных блоков, вместо этого ядро могло обрабатывать любую рабочую нагрузку.

Унифицированный конвейер пикселей и вершин. Все устройства могут разговаривать с памятью через текстурные блоки и передавать данные между ними через буфер атрибутов.
Так что же тогда произошло? ALU — устройства, выполняющие математические инструкции, были уже похожи. Изменилось то, что различие между блоками было полностью устранено. Вершинные шейдеры теперь выполнялись в тех же блоках, что и пиксельные. Это позволяет сбалансировать рабочую нагрузку между работой вершинного и пиксельного шейдеров. Вы должны заметить здесь, что вершинные и пиксельные шейдеры должны каким-то образом общаться. Для хранения атрибутов для интерполяции необходим, например, цвет вершин. Вершинный шейдер будет вычислять атрибуты каждой вершины последовательно, но пиксельный шейдер может зависеть от этой информации некоторое время, пока все пиксели не будут обработаны. Мы вернемся к этому моменту позже, давайте сейчас просто запомним.
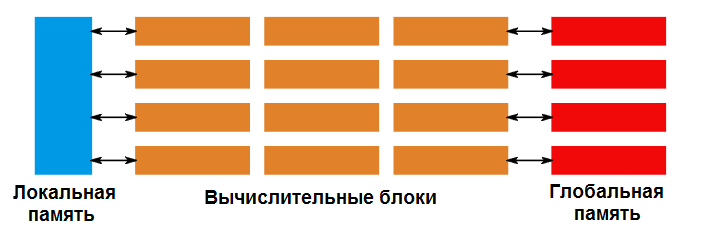
Унифицированный конвейер, показанный как вычислительный конвейер. Буфер атрибута становится локальной или разделяемой памятью, текстурные блоки становятся шлюзом в глобальную память, а пиксельные и вершинные блоки теперь являются общими вычислительными единицами.
Эта модель (несколько соединенных вместе ALU с дополнительной памятью, позволяющей обмениваться данными между множествами из них) была введена одновременно с «вычислительным шейдером». На самом деле есть еще несколько деталей. Например, вычислительный блок обычно обрабатывает не один элемент, а несколько, и есть еще немало кэшей, чтобы сделать все это эффективным. Ниже приведена диаграмма для одного вычислительного блока в архитектуре AMD GCN. Обратите внимание: то, что я ранее называл «вычислительный блок», теперь является «SIMD», это более важно в данный момент.
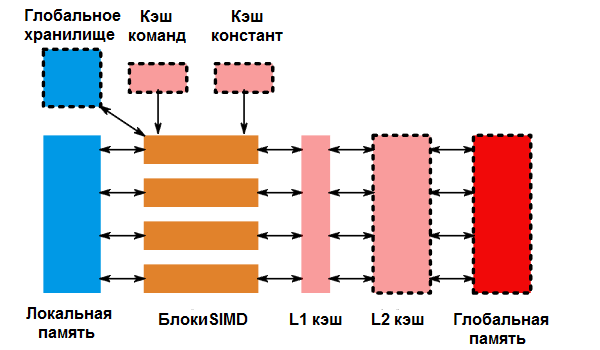
Вычислительный блок класса AMD GCN, состоящий из четырех 16-разрядных блоков SIMD, локальной памяти и различных кэшей. Выделенные пунктиром устройства разделяются между несколькими вычислительными блоками.
Надо знать, что другие графические процессоры очень похожи на этот. Я использую GCN здесь просто потому, что больше всего с ним знаком. На оборудовании NVIDIA вычислительный блок GCN отображен как «потоковый мультипроцессор» или SM. SIMD имеют разную ширину, и кэши будут выглядеть несколько иначе, но основная вычислительная модель все равно будет одинаковой.
Вернемся к блоку SIMD. Графические процессоры всегда оптимизированы для одновременной обработки многих вещей. Где у вас один пиксель, там их еще несколько, так были спроектированы аппаратные средства. В случае GCN инженеры сделали четыре 16-разрядных SIMD в каждый вычислительный блок. SIMD (сокращение для “одиночный поток команд, множественный поток данных”) может выполнять одну операцию по 16 элементам одновременно. Не за один такт — есть некоторое время ожидания. Но для GCN эта задержка составляет четыре цикла. Поэтому имея 4 SIMD и притворяясь, что SIMD не 16, а 64 в ширину, машина ведет себя как если бы она выполняла 64 инструкции за цикл. Смущены? Не волнуйтесь, это всего лишь особенность реализации, так как каждый графический процессор выполняет несколько команд вместе, будь то 64 в случае GCN или 32 на существующих архитектурах NVIDIA.
В результате мы получили графический процессор, состоящий из множества вычислительных блоков, и каждый вычислительный блок, содержащий:
- Множество SIMD-процессоров, которые выполняют инструкции.
- Некоторую локальную память внутри каждого вычислительного блока, которая может использоваться для связи между этапами шейдера.
- Каждый блок SIMD, который выполняет одну команду для многих элементов.
С этими предпосылками давайте посмотрим, как они могут обнаружить себя, если не выполняют работу пиксельных и вершинных шейдеров. Идем дальше!
Ядро
Цель состоит в том, чтобы написать систему программирования, которая позволяет использовать подручные аппаратные средства. Очевидно, первое, что мы замечаем, это то, что мы хотим избежать. Все вычислительные блоки являются клиентами кэша L2. Но, очевидно, кэши L1 могут выйти из синхронизации. Поэтому, если мы распределяем работу, мы должны притворяться, что не можем говорить о вычислительных блоках. Это означает, что мы как-то должны разделить работу на более мелкие части. Мы могли бы просто притворяться, что нет вычислительных блоков и отправки отдельных элементов, но тогда мы теряем местную память. Поэтому кажется, что нужен еще один уровень ниже «вся работа тут».
Мы могли бы перейти непосредственно на уровень SIMD. Но это не оптимально, так как есть возможность, которую мы еще не обсуждали про вычислительные блоки. Поскольку у нас есть какая-то локальная память, естественно предположить, что мы можем использовать ее для синхронизации блоков SIMD (учитывая, что мы могли бы просто написать что-то в локальную память и дождаться его появления). Это также означает, что мы можем синхронизировать только в одном вычислительном блоке. Поэтому давайте использовать его в качестве следующего уровня группировки. Мы будем называть работу, которая ставится на единый вычислительный блок, рабочей группой. Таким образом, мы начинаем с рабочего домена, который затем разбивается на рабочие группы. Каждая рабочая группа работает независимо от других. Учитывая, что разработчик может не знать, сколько групп может работать одновременно, мы обеспечиваем, чтобы рабочие группы не зависели от того, что:
- Обрабатывается другая рабочая группа из того же домена.
- Рабочие группы внутри домена выполнялись в любом конкретном порядке.
Это позволяет нам запускать одну рабочую группу за другой на одном устройстве или все сразу. Теперь внутри рабочей группы нам все еще нужно много самостоятельных элементов работы, поэтому мы можем заполнить все SIMD-модули. Давайте назовем отдельный элемент работы рабочим элементом, и наша модель программирования запустит рабочие группы, содержащие множество рабочих элементов. По крайней мере, достаточно, чтобы заполнить один вычислительный блок (мы, вероятно, хотим больше, чем просто заполнить, но об этом позже).
Давайте объединим все это: наш домен состоит из рабочих групп, каждая рабочая группа отображается на один вычислительный блок, а модули SIMD обрабатывают рабочие элементы.
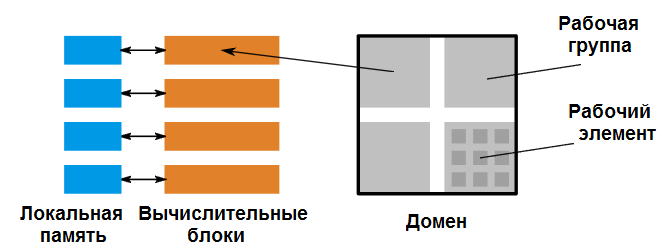
Вот как наша модель программирования теперь отображается на аппаратные средства. Домен состоит из рабочих групп, которые присваиваются вычислительным блокам. Каждая рабочая группа состоит из нескольких рабочих элементов.
Мы забыли, что по-видимому, есть еще один уровень, который мы не покрывали. Я упомянул, что SIMD-модуль обрабатывает несколько рабочих элементов вместе. Но мы не раскрыли это в модели программирования, у нас есть только «независимые» рабочие элементы. Давайте дадим работающим элементам вместе имя. Мы назовем их подгруппой (у AMD они обычно называются «wavefront», в то время NVIDIA называет «warp».) Теперь мы можем предоставить другой набор инструкций, которые выполняют операции во всех элементах SIMD. Например, мы могли бы вычислить минимум всех значений не проходя через локальную память.
Я уже упоминал, что ограничений на порядок накладывается очень мало. Например, графический процессор может захотеть выполнить весь домен на одном вычислительном блоке. Одной из причин этого является латентность памяти. Эти широкие SIMD-устройства великолепно щелкают числа, но также это значит, что доступ к памяти относительно сильно замедлен. На самом деле, он ужасно медленный. GCN CU может обрабатывать 64 инструкции умножения-сложения с плавающей запятой за цикл, что составляет 64 × 3 × 4 байта входных данных и 64 × 4 байта на выходе. Через большой чип, такой как Vega10, это 48 кб чтения за один цикл. На 1,5 ГГц, это 67 Тб данных, которые нужно прочитать. Системы памяти GPU были оптимизированы для большой пропускной способности ценой латентности, и это влияет на то, как мы их программируем.
Прежде чем мы рассмотрим последствия данной модели программирования, давайте подведем итог тому, как выглядят вычислительные шейдеры:
- Работа определяется с помощью трехуровневой иерархии:
- Домен определяет всю работу.
- Домен подразделяется на рабочие группы, которые выполняются независимо, но допускают связь внутри группы.
- Рабочие элементы — это отдельные элементы для обработки.
- Некоторые API также выставляют промежуточный уровень — подгруппу, которая допускает некоторые оптимизации ниже рабочей группы, но выше уровня рабочего элемента.
- Рабочие группы могут синхронизироваться внутренне и обмениваться данными через локальную память.
Эта модель программирования универсальна во всех API-интерфейсах для вычислительных шейдеров GPU. Различия в предоставляемых гарантиях. Например, API может ограничить количество рабочих групп в полете, чтобы вы могли синхронизировать их между собой. Или какое-то оборудование может гарантировать порядок выполнения, чтобы вы могли передавать информацию из одной рабочей группы в другую.
Сокрытие латентности и как писать код
Теперь, когда мы понимаем, как выглядят аппаратное обеспечение и модель программирования, как реально программировать это? До сих пор, похоже, мы писали обычный код. Мы обрабатываем в нем рабочий элемент, потенциально обмениваясь информацией между соседями на одном SIMD, с другими через локальную память и, наконец, читаем и пишем через глобальную память. Проблема в том, что «нормальный» код не очень хорош, так как нам нужно скрыть латентность.
Способ, которым GPU скрывает латентность тем, что у него больше работы в полете. Намного больше работы, например, у той же GCN каждый вычислительный блок может иметь в полете до 40 подгрупп. Каждый раз, когда подгруппа обращается к памяти, другая получает назначение в планировщике. Учитывая, что только четыре могут выполняться одновременно, это означает, что мы можем переключиться до 10 раз, прежде чем вернемся в подгруппу, которая начала исходный запрос.

Первая подгруппа попадает в инструкцию памяти и приостанавливается. Вычислительный блок немедленно планирует следующую подгруппу, которая также приостанавливается. После того, как четвертая подгруппа выдала инструкцию, подсистема памяти вернется, и обработка первой подгруппы может возобновиться. Таким образом, вычислительный блок выполняет работу в каждом цикле.
Однако здесь есть проблема. Переключение подгрупп должно быть мгновенным, чтобы сделать подобное возможным. Это означает, что вы не можете записать состояние программы в память и прочитать его обратно. Вместо этого все состояния всех программ постоянно хранятся в регистрах. Для этого требуется огромное количество регистров. Единичный вычислительный блок GCN имеет 256 кб регистров. При этом мы можем использовать до (256 кб/40/4/64 б) = 24 регистра для одного элемента, прежде чем потребуется уменьшить их занятость. Для нашего стиля программирования это означает, что мы должны попытаться свести к минимуму количество состояний, которых приходится поддерживать как можно больше хотя бы пока есть доступ к памяти. Если мы не получаем доступ к памяти, один вейвфронт может держать SIMD на 100% занятым. Мы также должны быть уверены, что используем эту локальную память и кэш-память L1 насколько это возможно, поскольку они имеют пропускную способность больше и задержку меньше, чем внешняя память.
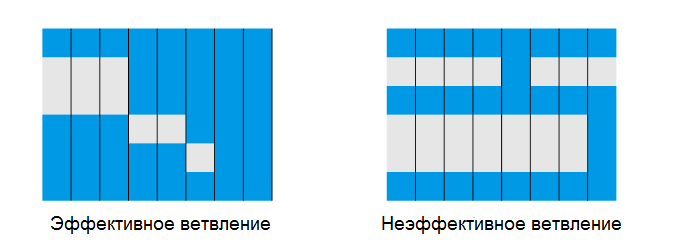
Один SIMD может обрабатывать несколько рабочих элементов за один такт, на этом рисунке он имеет ширину 8. Если ветка короткая, мы не тратим много усилий. Длинные ветки, которые отключают большинство SIMD-полос, могут значительно снизить пропускную способность.
Другая проблема, с которой мы столкнемся: как обрабатываются ветви. SIMD обрабатывают все вместе, поэтому они не могут выполнять переходы. Вместо этого отдельные полосы маскируются, т.е. не участвуют в работе. Это также подразумевает, что если все рабочие элементы не занимают одну и ту же ветвь. GPU, как правило, выполняет обе стороны ветки.
Это означает, что для SIMD длины N мы можем получить наихудшее использование как 1/N. На процессорах N обычно от 1 до 8, поэтому катастрофы нет. Но на графическом процессоре N может достигать 64, а это уже важно. Как мы можем убедиться, что так не происходит? Во-первых, мы можем воспользоваться выполнением подгруппы. Если у нас есть ветка, где надо выбрать между дешевой и дорогой версией, а некоторые рабочие элементы занимаются дорогой, мы могли бы отправить на дорогую все из них. Это снижает стоимость ветки с дорогая + дешевая до просто дорогой. Другая часть — просто избежать чрезмерного ветвления. По мере расширения CPU это становится все более важным, и методы, такие как сортировка всех данных и обработка становятся более интересными, чем интенсивное ветвление на отдельных рабочих элементах. Например, если вы пишете механизм моделирования частиц, гораздо быстрее сортировать частицы по типу и запускать специализированную программу моделирования для каждой, а не все возможные.
Что мы узнали? Нам нужно:
- Большая область задач — чем больше самостоятельных рабочих элементов, тем лучше.
- Код с интенсивным использованием памяти должен минимизировать количество состояний, чтобы обеспечить высокую загрузку.
- Мы должны избегать ветвей, которые выводят из работы большую часть подгруппы.
Эти рекомендации будут применяться повсеместно ко всем графическим процессорам. В конце концов, все они были спроектированы для решения широкомасштабных параллельных графических задач, поэтому у них мало ветвлений, не слишком много состояний в полете, и тысячи тысяч самостоятельных рабочих элементов.
Заключение
Я надеюсь, что этот пост даст вам представление о том, как мы пришли к вычислительным шейдерам. Действительно интересно, что концепции минимального общения, доступа к локальной памяти и расхождения стоимости абсолютно универсальны. Современные многоядерные процессоры также вводят новые уровни затрат на общение с памятью, для моделирования затрат уже давно используется NUMA и т.д. Понимая, что не вся память равна, и что на лежащих в основе аппаратных средствах ваш код выполняется каким-то определенным образом, вы сможете выжать больше производительности везде!
