Тред про game audio: Как синтезировать речь персонажа из простых звуков

Перевод треда Kevin Regameyk с рассказом, как он смог синтезировать речь Селесты из одноименной игры.
Создание диалогов Селесты — тема вопросов №1, когда дело касается звука в игре. Расскажу о том, как мы их создавали.
Во-первых, мы исследовали несколько простых синтезаторных звуков, чтобы определить общий тон для голоса данного персонажа. Когда был установлен основной тембр, мы перешли к настройке, как этот тон может меняться со временем.
По сути, используя параметрический эквалайзер в FL Studio, мы смоделировали так называемые «форманты» — то есть естественные спектральные пики в человеческих гласных звуках. У этих спектральных пиков есть определенные частотные положения и отношения, и они выглядели примерно так:
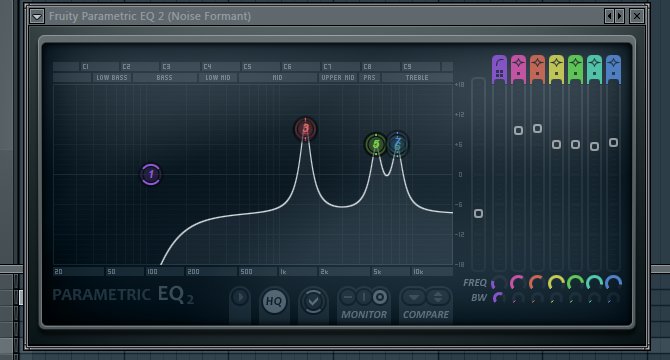
Затем мы настроили частотные положения этих пиков во времени, чтобы они напоминали то, как человеческий голос может изменяться между гласными звуками.
Затем мы составили эмоциональный диапазон данного персонажа и выяснили, какими могут быть звуковые характеристики этих эмоций.

Эмоции обычно высокие или низкие? Они однородны или сильно изменяются? Речь идет медленно и осторожно или быстро и отрывисто? Какую высоту звука мы должны слышать и какие предложения представляют собой эти звуки?

Попросту, я часто читал сценарий и «переигрывал» диалоги.

Затем мы нажали PLAY в FL Studio (чтобы запустить автоматизацию формант) и после этого «исполнили» эмоции на миди-клавиатуре пианино, возясь с колесом высоты тона в попытке достичь всех тех характеристик, которые изложили выше.
Мы записали аудиовыход этого выступления на отдельный компьютер, а затем просмотрели и выбрали «хорошие дубли». Эти хорошие результаты были разделены на 3 основные категории по эмоциям:
- Быстрое прохождение слогов (20)
- Слоги с ударением (10)
- Окончания предложений (10)
Используя @fmodstudio, мы настроили систему событий, управляемую эмоциями (на самом деле изображениями эмоций персонажа)… У нас было одно звуковое событие для каждого персонажа, и каждое диалоговое событие воспроизводится без остановки в течение всего разговора данного персонажа в игре.
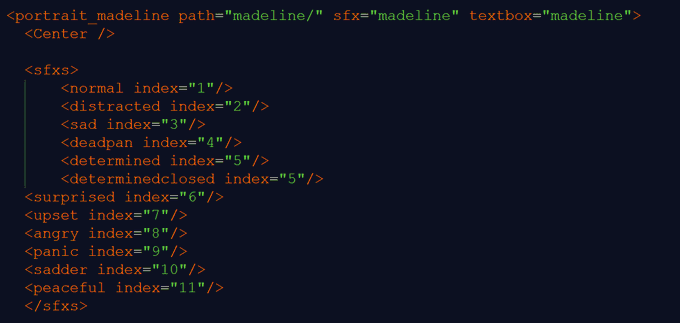
Мы зацикливаем тишину, пока не наступит очередь данного персонажа говорить. Когда этот персонаж говорит, сторона кода отправляет информацию об изображении текущего персонажа в FMOD, а FMOD отвечает, отправляя точку воспроизведения в соответствующую эмоцию на временной шкале события.
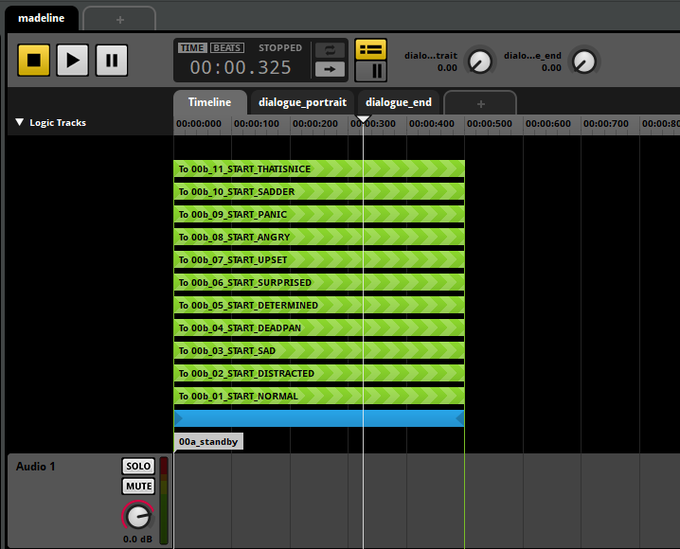
Когда мы достигаем данной эмоции, мы проходим через случайную последовательность слогов с помощью построенной нами системы переходов. Ее создание было довольно утомительным, потому что при перемещении по случайной последовательности аудиофайлов FMOD не может отлично обрабатывать такую степень точности.
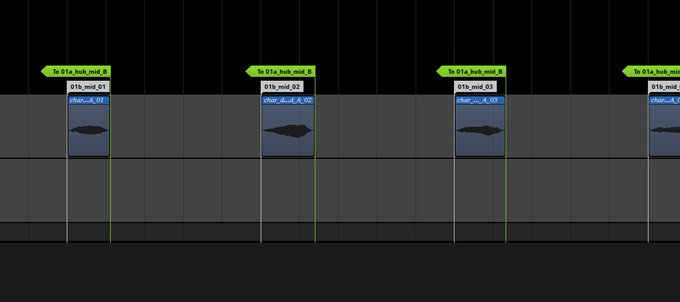
Это потребовало вручную разместить каждый слог на временной шкале и настроить «переходный узел», который бы быстро отправлял точку воспроизведения к этим различным слогам. Ни один слог не мог воспроизводиться дважды подряд, а вероятность воспроизведения подчеркнутых слогов была ниже.
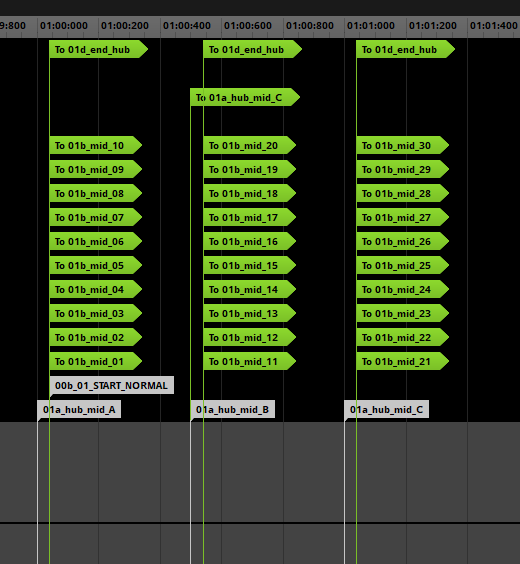
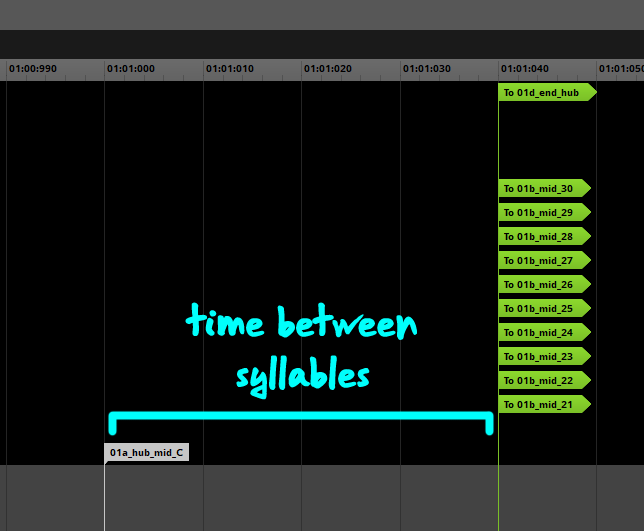
Хаб также сделал тривиальной настройку интервала между слогами (поскольку мы могли перемещать всю позицию хаба, а не сорок отдельных маркеров перехода).
В любом случае, как только отрисовка текста в пользовательском интерфейсе игры заканчивается, FMOD получает уведомление о том, что речь должна завершиться. Затем ползунок возвращается в режим ожидания следующего изображения / эмоции. (Он либо проигрывает последний слог перед возвратом, либо сразу же возвращается, если был на подчеркнутом слоге).
Вот и все! Надеюсь, вы узнали что-нибудь о #gameaudio! Если хотите увидеть подробную разбивку того, как работает диалоговое событие, можете посмотреть его здесь:
https://www.twitch.tv/videos/248998904?sr=a&t=1250s
Вы также можете скачать и попробовать всю @celeste_game
Проект FMOD (со всеми исходными звуками и музыкой — спасибо @kuraine!) доступен на сайте. https://fmod.com/resources/documentation-studio?version=2.00&page=appendix-a-celeste.html
Всем привет!
Ссылка на тред: https://twitter.com/regameyk/status/1416483668869062656
