Кроссплатформенный движок игровой графики — 2

Если мы подробнее рассмотрим любой современный графический API для ПК, мы можем выделить в нем два основных компонента. Один для распределения и управления графической памятью, как правило, в виде текстур, буферов, кучек, представлений/дескрипторов и т. д., другой — для выдачи команд к вашему GPU через некоторый тип абстрактного списка команд или контекстный API устройства. Это основные инструменты вашего движка для связи с вашим графическим драйвером, который, в свою очередь, передает информацию для аппаратных средств графики.
Два основных компонента графического API
Н адо стараться, чтобы эти два компонента работали правильно и эффективно в любом графическом приложении, которое вы пишете. Основная идея в том, что вам необходимо взаимодействовать с ними как можно реже, поскольку каждый вызов драйвера устройства имеет определенную стоимость для CPU. Резервированные вызовы API также могут негативно повлиять на производительность графического процессора, так как различные изменения состояния могут нести связанные с ними скрытые служебные данные (смотрите, например, превосходную статью от AMD с демонстрацией переключений контекста).
Для единой аппаратной платформы и единого графического API ситуация может усложниться. В эпоху создания консольной графики на ПК нам приходится брать на себя обязанности, прежде возложенные на драйвер, поэтому сложно отслеживать, что на самом деле означает минимальное и эффективное использование API. Обычно нет единого правильного способа сделать что-то, поэтому нужно экспериментировать и выяснять, что работает для вашего приложения, и что вы хотите предоставить пользователям вашей библиотеки. Добавьте несколько дополнительных платформ и графических API для поддержки, и неэффективное использование начнется очень быстро.
Я хотел бы познакомить вас с моделью управления ресурсами и представлением команд, где каждая платформа имеет право принимать правильные для себя решения, независимо от того, что может понадобиться другой платформе. В дополнение к этому я хочу гарантировать правильную многопоточную поддержку в этой модели, чтобы мы могли эффективно масштабировать код подачи команд до такого количества потоков, которое нам бы хотелось. Давайте начнем с гибкой настройки управления ресурсами.
Создание и управление ресурсами GPU
Позвольте мне сначала объяснить, что я имею в виду, когда говорю «ресурс GPU». Ресурс — это любой объект, созданный вашим базовым графическим API, который может использоваться, обрабатываться или проверяться с помощью какой-либо формы API подачи команд (например, список команд или контекст устройства). Это определение охватывает довольно широкий диапазон элементов, от кучи памяти, буферов и текстур до таблиц дескриптора, объектов состояния конвейера и корневых подписей (или их эквивалентов в выбранном вами API).
Прежде чем рассказывать про отправление команд, нужно объяснить, как мы хотим представлять ресурсы при их использовании в командах. Для моих целей представление идет в виде непрозрачных типов дескрипторов.
Дескрипторы по существу являются строго типироваными целыми числами. Вы можете реализовать их различными способами: обернуть целочисленный тип в структуру или определить класс перечисления с базой целочисленного размера. Важно то, что они строго типированы. Вам не нужна возможность присвоить дескриптор, представляющий дескрипторную таблицу, дескриптору, представляющему 2D-текстуру, например.
// Пример строго типированного 32-битного дескриптора, использующего enum
// Важно: typedef или оператор using здесь не работают, потому что строгого типирования не дают
enum class Tex2DHandle : uint32 { Invalid = 0xFFFFFFFF };
// Тот же тип дескриптора со структурным подходом
struct Tex2DHandle { uint32 m_value; };
Дескриптор станет уникальным представлением для данного ресурса. Сам дескриптор полностью непрозрачен и не будет передавать какую-либо прямую информацию о том, какой ресурс он представляет (насколько это касается вашего приложения, по крайней мере). Это дает основополагающей системе свободу представлять и организовывать ресурсы таким образом, каким она хочет. Ей всего лишь надо гарантировать, что существует взаимно однозначное отображение закодированного дескриптора на любое поддерживающее представление.
Использование дескрипторов для представления ресурсов имеет несколько отличных преимуществ. Я назвал одно из них выше: движку дается контроль над тем, как ресурсы представлены и выложены. Еще одно заключается в том, что вам не надо заморачиваться созданием единого интерфейса для представления ресурса на разных платформах. Иногда вы увидите виртуальный интерфейс для ресурсов или общие классы, которые предоставляют реализации для разных платформ с использованием препроцессора. Эти типы конструкций с течением времени приходят в беспорядок, особенно когда их поддерживают различные люди на разных платформах. Дескрипторы не подталкивают вас к подобным решениям, вместо этого они дают платформе возможность представлять ресурс, как удобно в ее родной среде.
Еще один классный аспект заключается в том, что дескрипторы упрощают представление ресурсов как чистых данных. Нет окружающего ресурс API. Отсутствуют способы вызова, которые будут изменять размер текстуры или генерировать mips, или сделать какую-либо другую случайную операцию, и вы не столкнетесь с соблазном добавить больше раздутых и ненужных операций. Нет болезненных ситуаций, когда графические API-интерфейсы полностью несовместимы (например, таблицы дескрипторов и виды ресурсов).
Я предпочитаю даже не предлагать способ запроса каких-либо свойств ресурса (например, ширины текстуры, высоты, подсчета mip и т.д.). Идея в том, что если ваше приложение может запросить ресурс с заданным набором свойств в одной точке его жизни, оно должно хранить эти свойства где-то в подходящей для себя форме, если они будут интересны позже. Речь идет об очень четко определенном случае использования для данных и об определении очень четких минимальных обязанностей для вашего движка вокруг этих данных. Дескриптор ресурса может быть создан, уничтожен или использован в API представления команд. Вот и все.
Последнее свойство дескрипторов, которое я явно хочу назвать, заключается в том, что отпадает необходимость в указателях или ссылках на ресурсы в вашем движке. Значительно улучшается история отладки. 32-разрядный дескриптор имеет более чем достаточное пространство для кодирования информации о проверке конкретной реализации всего, что он должен представлять. Это означает безопасный доступ к ресурсам в любое время и правильную отчетность об ошибках в случае, если неверный дескриптор передан на уровень движка.
Мы немного поговорили о дескрипторах и теперь можем посмотреть, как будем использовать их во время отправки работы в GPU.
Отправка команд: конкуренция состояний
Давайте уточним, что мы хотим получить от системы подачи команд. Я уже упоминал как масштабируемость по нескольким потокам, так и минимальное взаимодействие с базовым API, но есть еще несколько вещей, которые хочу достичь. Одна из них — способ избежать утечки состояния.
Собственные API отправки команд (например, ID3D11DeviceContext или ID3D12GraphicsCommandList) в известной степени содержат состояния. Вы вставляете в них кусочки состояния или переворачиваете несколько переключателей перед выдачей операции, такой как вызов отрисовки или запись вычислений. Любая операция от установки буфера вершин до привязки состояния конвейера фактически изменяет состояние в API вашей команды. В этом нет ничего неправильного, но сохраненное состояние нередко влечет за собой побочные эффекты. Одним из них является так называемая утечка состояния, и по мере роста кода она может приносить все больше вреда.
Возьмите как пример следующий псевдокод:
void RenderSomeEffect()
{
// Установка всего нужного для вызова отрисовки
SetBlendState(...);
SetShaders(...);
...
// Связать текстуру со слотом 1
SetTexture(1, ...);
Draw(...);
}
void RenderSomeOtherEffect(EffectOption options)
{
// Настройка отрисовки
SetShaders(...);
SetDepthState(...);
...
Draw(...);
}
void RenderAllTheThings()
{
RenderSomeEffect();
RenderSomeOtherEffect(...);
}
Состояние смешивания, установленное в RenderSomeEffect, будет просачиваться в визуализацию, которую мы делаем с RenderSomeOtherEffect, поскольку эти вызовы происходят один за другим, а RenderSomeOtherEffect не указывает собственное состояние смешивания. В некоторых кодах это может быть желательным поведением, но зависимость от утечки часто вызывает странные ошибки при удалении состояния из системы. Все, что отображается в RenderSomeOtherEffect, иногда начинает полагаться на установки состояния смешивания в RenderSomeEffect, что может вызвать очень раздражающие ошибки при изменении или перемещении RenderSomeEffect.
К счастью, отказ от утечки состояния не слишком сложен. Первым шагом, который нам нужно предпринять, является создание API-интерфейса, ориентированного на приложения, в котором четко определено время жизни состояния или область действия. Целью области является четкое определение границ, когда устанавливается часть состояния, и когда эта часть состояния снова становится недействительной, подобно концепции RAII в C++. Вы можете определить область состояния на разных уровнях детализации, но в этом примере мы рассмотрим два уровня охвата: область прохода визуализации (render pass) и область пакета draw/dispatch.
Область прохода визуализации длится в течение выполняемого в данный момент отрезка визуализации и определяет только те части состояния, которые требуются всеми рисунками или отправлениями, выполняемыми в этом проходе. Она может включать в себя набор целей визуализации, буфер глубины, корневую подпись прохода и любые ресурсы конкретного прохода или просмотра (т.е. текстуры, буферы констант и т.д.).
// Пример данных прохода визуализации. Реализация зависит от вас!
struct RenderPassData
{
RootSignature m_passRootSignature;
RenderTargetHandle m_renderTargets[8];
DepthTargetHandle m_depthTarget;
ShaderResourceHandle m_shaderResources[16];
...
};
// Вы должны реализовать область как структуру RAII
// Не переживайте насчет аргумента CommandBuffer, мы скоро поговорим об этом!
RenderPassScope BeginRenderPassScope(CommandBuffer& cbuffer, const RenderPassData& passData);
// Еще вы можете дать простые функции begin/end
void BeginRenderPassScope(CommandBuffer& cbuffer, const RenderPassData& passData);
void EndRenderPassScope(CommandBuffer& cbuffer);
Область охвата пакета — это область, которая длится только для одной операции рисования или отправки, и по существу является полностью определенным описанием всего ресурса, необходимого для полного выполнения рисования или отправки (вне того, что было установлено в области прохода визуализации). Для пакетов рисования она может включать в себя вершинные и индексные буферы, состояние графического конвейера, примитивную топологию, все привязки ресурсов для каждого рисования и тип рисования, который вы хотите исполнить, со всеми его параметрами.
Пакет вычислений проще в том, что он просто определяет состояние вычислительного конвейера, набор привязок ресурсов для каждого отправления и тип отправки (обычный или косвенный) с сопутствующими параметрами. Вы можете выбрать, разрешено или нет рисовать и вычислять пакеты с временным переопределением любых из ресурсов, которые заданы в области прохода визуализации.
// Пример того, как может выглядеть пакет визуализации. Опять, это зависит от вас!
struct RenderPacket
{
PipelineState m_pipelineState;
VertexBufferView m_vertexBuffers[8];
IndexBufferView m_indexBuffer;
ShaderResourceHandle m_shaderResources[16];
PrimitiveTopology m_topology;
...
};
// Пример операции отрисовки с использованием пакета визуализации
void DrawIndexed(CommandBuffer& cbuffer, const RenderPacket& packet);
С данной установкой у вас есть гарантия, что из какого-либо рисования или прохода визуализации не сможет просочиться состояние. Новая область прохода визуализации не может начаться до тех пор, пока предыдущая не закончится (вы можете легко обеспечить это), а завершение области означает, что все состояние, определенное этой областью, недействительно. Взаимодействие приложения с вашим слоем движка в теперь относительно безопасно. От вас теперь зависит, как гарантировать безопасность и оптимальное использование API во внутренних компонентах вашего движка.
Вот пример псевдокода, как может выглядеть работа с областями охвата:
void RenderSomeRenderPass(CommandBuffer& cb, const array_view<RenderableObject>& objects)
{
// Начало с областью прохода визуализации
// Это привяжет все состояния, которые передались GetRenderPassData
// Поскольку мы используем RAII, эта область закончится с окончанием тела данной функции
RenderPassScope passScope = BeginRenderPassScope(cb, GetRenderPassData());
// Построить пакеты визуализации для объектов и отправить на выполнение
for (const RenderableObject& obj : objects)
{
RenderPacket packet = BuildRenderPacketForObject(obj);
DrawIndexed(cb, packet);
}
}
Отправка команд: запись и выполнение
До сих пор мы обсуждали, как мы взаимодействуем с ресурсами и состоянием. Чтобы связать все это вместе, давайте поговорим о записи, отправке и выполнении команд.
Написание типичного уровня абстракции заманчиво начать вокруг концепции списка команд. Вы можете создать класс списка команд с API для записи операций GPU, таких как отправка пакетов или выполнение операций копирования памяти. Как я намекнул в одном из фрагментов псевдокода выше, я хотел подойти к вещам несколько иначе. В идеале я хотел бы, чтобы мой графический код приложения был отделен от прямого взаимодействия с API, подобным D3D или Vulkan. Для этого мы можем ввести понятие командных буферов.
Командный буфер — это кусок памяти, в который мы вносим последовательность команд. Команда представляет собой комбинацию заголовка или кода операции, за которым следуют параметры для этой команды (например, команда «нарисовать пакет визуализации» будет иметь соответствующий код операции, за которым следует полное описание пакета). Мы в основном пишем программу высокого уровня, а затем отправляем ее на уровень движка для интерпретации. Это превращает уровень движка в сервер, который обрабатывает полную последовательность команд за один раз, а не принимает команды одну за другой.
Построение API вокруг концепции буфера команд очень просто, так как вы находитесь в точке, где почти непосредственно реализуете концепцию «видеоплеера», о которой я говорил в первой части. API-интерфейс командного буфера может быть простым набором бесплатных функций, которые толкают команды в ваш буфер. Если вы хотите поддерживать новую платформу, выполняющую какую-то экзотическую операцию, совершенно нормально ввести новый набор функций, добавляющих поддержку этих команд только на этой платформе. Мы не используем какие-либо интерфейсы, раздутые классы списка команд, pImpl и другую чрезмерно сложную C ++ ерунду. Достаточно простого расширяемого C-подобного API.
void Draw(CommandBuffer& cb, const RenderPacket& packet); void DrawIndex(CommandBuffer& cb, const RenderPacket& packet); void DrawIndirect(CommandBuffer& cb, const RenderPacket& packet, BufferHandle argsBuffer); void Dispatch(CommandBuffer& cb, uint32 x, uint32 y, uint32 z); void CopyResource(commandBuffer& cb, BufferHandle src, BufferHandle dest); #if defined (SOME_PLATFORM) void ExoticOperationOnlySupportedOnSomePlatform(CommandBuffer& cb); #endif
Когда дело доходит до реализации командных буферов на уровне движка, вы получаете полный контроль над переводом буферов команд в собственные вызовы API. Вы можете переупорядочивать команды, сортировать их, добавлять новые или даже прямо игнорировать некоторые из них, если это подходит для вашей конкретной платформы (некоторые операции могут не поддерживаться на вашей платформе, но их можно игнорировать!). Дескрипторы могут быть интерпретированы так, как слой движка считает нужным (помните: в командных буферах нет голых указателей!). При реализации этого всегда помните о схеме буфера команд, логике парсинга и логике обработки дескриптора ресурса с точки зрения доступа к памяти. Сохраняйте согласованность кеширования с приоритетом эффективного использования графического API, поскольку плохие шаблоны доступа к памяти обязательно будут убивать производительность в такой системе.
Отправка команд: расширение потока
Поскольку мы используем концепцию изолированных командных буферов, многопоточная командная запись становится легкой (обращаться к любому виду общего или глобального состояния при записи командного буфера неправильно!). Делить один командный буфер на несколько потоков может быть небезопасно, но у вас никогда не должна возникнуть такая ситуация. Командные буферы должны быть маленькими и дешевыми, поэтому делайте их больше!
С точки зрения многопоточности у этой головоломки есть один недостающий кусок. Многопоточная запись и отправка собственных списков команд графического API (если они доступны вам). Для этого я использую модель, которую хотел бы назвать моделью записи-постановки-совершения.
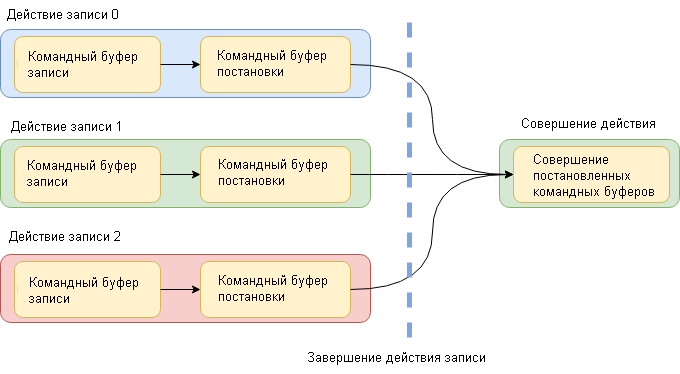
Модель записи-постановки-совершения
Аспект записи — это то, о чем мы говорили вначале: запись команд в объекты командного буфера с использованием нашего С-подобного API-интерфейса. Аспект постановки состоит из двух частей: первая — это фактический перевод нашего командного буфера в собственный список команд. С API, подобным D3D12, это означало бы создание объекта ID3D12GraphicsCommandList. Второй аспект постановки — создание очереди из списка команд для выполнения вместе с ключом сортировки, определяющим, когда он должен совершаться относительно других списков команд. Важно отметить, что вы должны полностью сохранить сквозной аспект, поскольку все это делается на многих потоках одновременно. Можно добиться этого, используя потоковое локальное хранилище или некоторую форму пригодной для потоков очереди, чтобы сформировать список команд и отсортировать пары ключей.
Теперь совершение становится связанным выполнением всех постановленных списков команд после завершения всех заданий записи и постановки. Операция совершения принимает все списки команд в очереди, сортирует их в соответствии с ключом сортировки и затем отправляет с помощью API наподобие ExecuteCommandLists. Такая модель дает API, в котором вы можете создавать большие графы работ по визуализации на любом нужном уровне детализации. Вы можете одновременно записывать все проходы визуализации на столько потоков, сколько хотите, в то же время гарантируя порядок при окончательном представлении.
Если вы работаете с D3D11 или OpenGL, и не можете легко создавать собственные списки команд по многим потокам, вы все равно можете выполнять многопоточную запись командных буферов. В этапе постановки будут только сырые командные буферы, а шаг совершения будет фактически анализировать и переводить эти буферы в собственные вызовы API. Это не так идеально, как случай многопоточной записи команд в D3D12 или Vulkan, но по крайней мере дает некоторую форму масштабируемости!
Дополнение: прикольные действия с командными буферами
Просто для забавы, вот список других хороших вещей, которые вы можете делать с буферами команд:
- Сохранять/загружать их с/на диск
- Создавать графический код в конвейере контента! Создавать собственные инструменты для захвата графики!
- Выгружать для отладки командные буферы последних этапов в случае связанного с графикой сбоя
- Использовать их в качестве пакетов программных команд чтобы оптимизировать визуализацию
- Пересылать по сети для удаленной диагностики графики
- Встраивать в вычислительный шейдер (не знаю, что это вам даст, но возможность есть!)
- Много чего еще!
Они имеют огромный потенциал для создания инструментов, отладки и оптимизации.
