Как работает графический процессор на низком уровне — небольшое введение от Adrian Jurczak

В этой статье кратко излагается часть низкоуровневых аспектов в работе графического процессора. Несмотря, что набор инструкций доступный для программирования GPU проще, чем для CPU, содержание этих инструкций также в точности не соответствует действиям оборудования. Причина кроется в том, что мы не можем просто запрограммировать графический процессор без какого-либо API, который является абстракцией над его внутренней работой. И несмотря на то, что в последние несколько лет появились более явные API, такие как DirectX 12 и Vulkan, которые сокращают этот разрыв между абстракцией и реальной работой оборудования, есть еще несколько низкоуровневых частей, которые стоит объяснить.
Примечание автора: хотя этот пост не о графическом или вычислительном API, я буду использовать некоторые термины, используемые в Vulkan, в основном потому, что это единственный современный и многоплатформенный API.
Содержание
Части графического процессора — краткое перечисление
Давайте перечислим наиболее важные части GPU на самом низком из возможных уровней:
- Блоки FP32
- FP 64 и/или SPU (специализированные вычислительные блоки)
- Блоки INT32
- Регистры
- встроенная память:
- L0$ (редко в оборудовании потребительского класса)
- L1$ используется совместно в разделяемой памятью (Shared Memory) на каждом вычислительном блоке
- L2$ на GPU
- внешняя память (память устройства)
- планировщик команд
- диспетчер команд
- TMU, ROP — фиксированные блоки конвейера
- …и другие
Все вышеперечисленное, конечно, сгруппировано во множество иерархий, которые в итоге составляют графические карты.
GPU — это одно большое устройство асинхронного ожидания
По крайней мере, так вы можете думать о нем с точки зрения CPU. Конечно, это намного сложнее, чем все доступное для взгляда со стороны процессора. Но все же логика остается. Вы отправляете какую-то работу и ждете результатов, занимаясь другими делами. Вам нужно обеспечить какую-то синхронизацию сделанного и несделанного. Fence в Vulkan — это основной механизм синхронизации CPU и GPU.
Ядра в GPU
Что ж, для многих это может быть сюрпризом, но так называемые ядра в мире графических процессоров — это скорее маркетинговый термин. Реальность намного сложнее. Ядра CUDA в картах Nvidia или просто ядра в графических процессорах AMD — это очень простые блоки, которые выполняют операции конкретно с плавающей точкой.1 Они не могут выполнять такие же причудливые вещи, как процессоры (например, прогнозирование ветвлений, выполнение вне очереди, выборку данных). В то же время они не могут работать самостоятельно. Ядра привязаны к группе соседей (что обсудим далее в параграфе «Скаляры и векторы»). С этого момента будем называть их модулями шейдинга. Хотя некоторые могут рассматривать ядра как очень примитивные, которые не могут работать сами по себе, мы также должны упомянуть вычислительный блок — гораздо более крупную аппаратную конструкцию, которая включает в себя многие из таких ядер. У вычислительного блока намного больше функций, чем у обычного ядра CPU: кэши, регистры и т.д. Есть элементы, специфичные для графического процессора: планировщик, диспетчер, ROP, TMU, интерполяторы, блендеры и многое другое. Хотя все это вместе может чем-то напоминать CPU, ни один из блоков нельзя считать ядром. Блок шейдинга слишком прост, а вычислительный — гораздо больше.
Каждый производитель имеет собственное название для вычислительного блока:
- Nvidia использует SM (Streaming Multiprocessor, многопроцессорную потоковую передачу)
- AMD использует CU (Compute Unit, вычислительный блок) и WGP (Workgroup Processor, процессор рабочей группы начиная с архитектуры RDNA)
- Intel использует EU (Execution Unit, исполнительный блок) и Xe Core (начиная с новой архитектуры Arc)
Стоит упомянуть, что начиная с архитектуры Тьюринга появилось два новых типа ядер: ядра RT и тензорные (AMD также имеет собственные ядра RT начиная с архитектуры RDNA2). Ядра RT ускоряют BVH (Bounding Volume Hierarchy, иерархию ограничивающих объемов)2, а тензорные ядра ускоряют операции FMA с матрицами с более низкой точностью (обычно для машинного обучения мы можем пренебречь 32-битными числами с плавающей точкой).
Вы можете использовать ядра RT и в картах AMD, и в Nvidia, с универсальными расширениями трассировки.
Тензорные ядра в графических процессорах Nvidia можно использовать напрямую с помощью VK_NV_cooperative_matrix. Она работает с 32-битными и 16-битными числами с плавающей точкой.
Если вам интересно узнать количество SM на своем GPU и вам нужно использовать эту информацию в коде, существует несколько вариантов (как минимум в Nvidia GPU):
- VkPhysicalDeviceShaderSMBuiltinsPropertiesNV
- Библиотека NVML — библиотека Nvidia поставляется с драйверами, но заголовочный файл на C распространяется с CUDA SDK
Одновременность и параллелизм
Теперь, когда мы знаем, из чего состоит вычислительный блок, давайте поговорим про одно заблуждение о происходящем внутри него. Я считаю, что понятия одновременности и параллелизма (concurrency and parallelism) слишком легко взаимозаменяемы во многих статьях. В целом подход SPMT (Single Program Multiple Threads) не позволяет нам использовать эту разницу: производители графических процессоров не раскрывают, что находится внутри SM / CU (за исключением размера разделяемой памяти и размера рабочей группы), и особенно скрывается сколько есть блоков шейдинга. Это основная причина, по которой подмена понятий не имеет значения при написании шейдеров. Но давайте прольем свет на то, что на самом деле происходит при отправке работы в GPU. Мы будем использовать схему потокового мультипроцессора из архитектуры Тьюринга Nvidia: Turing SM.
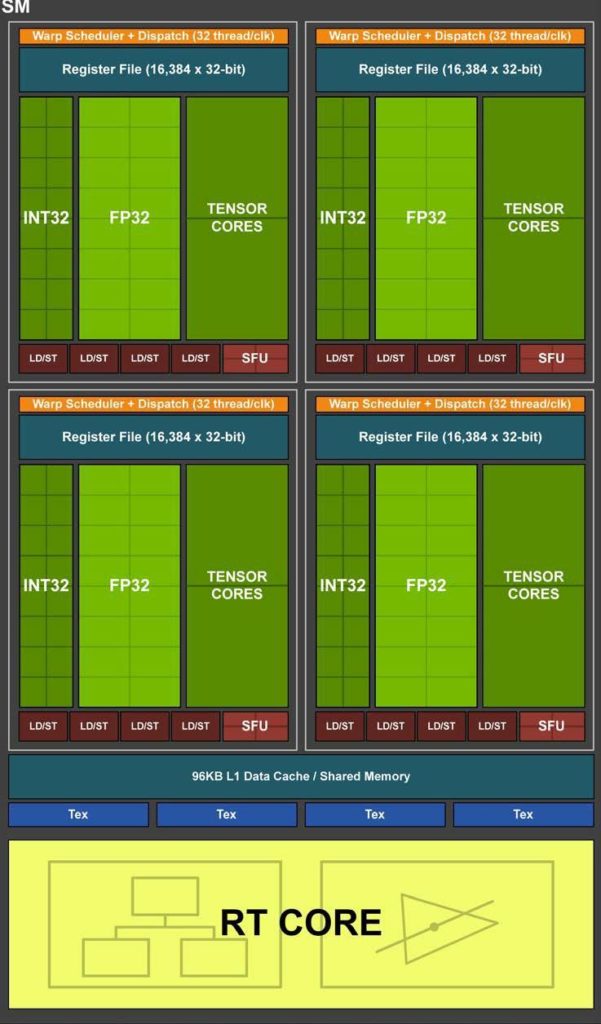
Как видите, каждый такой SM имеет 64 блока шейдинга FP32. Обратите внимание, насколько велики регистры. Теперь давайте воспользуемся немного надуманным примером и предположим, что мы распределяем работу 4 независимых подгрупп (128 потоков), содержащих только числа одинарной точности с плавающей точкой. Первая и вторая подгруппы (64 потока) могут выполняться параллельно, поскольку для их покрытия достаточно аппаратных модулей шейдинга. Третью и четвертую загрузят в регистр и заставят ожидать завершения / остановки предыдущего. Если происходит остановка, третья и четвертая будут выполняться одновременно с первой и второй. Конечно, может случиться, что, например, только 2-я подгруппа остановится, тогда 1-я и 3-я могут выполняться параллельно. Это различие в большинстве случаев не дает вам никаких преимуществ при написании кода, но теперь должно быть ясно, что оба случая — одновременный и параллельный — происходят в GPU и означают разные вещи.
Если вы пришли из мира CPU, то одновременность на графическом процессоре — это концепция, аналогичная SMT и Hyper Threading, но с другим масштабом.
Наименьший рабочий блок
Как только мы подготовим данные, их можно отправить в Workgroup. Рабочие группы — это конструкция, которая включает в себя как минимум один рабочий блок (соответствует одному аппаратному потоку), который представляется как единое целое. Это может быть одна операция или тысячи. Но для GPU не имеет значения, сколько данных мы предоставляем, потому что все они разделены на группы, соответствующие лежащему в основе оборудованию…
Наименьший исполнительный блок не равен наименьшему рабочему блоку
…и эти группы имеют разные названия в зависимости от производителя:
- Warp — у Nvidia
- Wave(fronts) — у AMD
- Wave — при использовании DX12
- Subgroup — при использовании Vulkan (начиная с 1.1)
Длина подгрупп зависит от производителя. У AMD было 64 числа с плавающей точкой на картах Vega, а теперь с Navi используется комбинация 32/64. Nvidia использует 32 числа с плавающей точкой. Intel, с другой стороны, может работать в конфигурациях 8/16/32.3 Размеры подгрупп имеют решающее значение для понимания разницы: хотя наименьший рабочий блок на самом деле представляет собой один поток, графический процессор будет запускать потоки размером не менее рабочей группы! Может показаться неоптимальным, но учитывая, что графические процессоры рассчитаны на огромное количество данных, это на самом деле очень быстро. Все неоптимальные комбинации данных, которые не соответствуют полностью подгруппе, смягчаются механизмом, называемым скрытие задержки.
Также стоит упомянуть, что мы обрабатываем данные группами, потому что растровые блоки выводят данные в виде квадов (а не отдельных пикселей), а исторически GPU могли обрабатывать только графические конвейеры. Квады необходимы для производных, которые позже будут использоваться сэмплерами (не вдаваясь в подробности: мы можем использовать mip-mapping благодаря этому конвейеру). В настоящее время производители оборудования стремятся сбалансировать размер подгруппы, потому что:
- меньшие подгруппы означают меньшую стоимость дивергенции, но также и меньшую коалесценцию памяти (эффективность)
- большие подгруппы означают дорогую диввергенцию, но увеличивают коалесценцию памяти (гибкость)
Регистровый файл и кэш
Прежде чем описывать, что такое скрытие задержки, надо понять один важный аппаратный аспект: размер регистра. Если бы мне надо было привести только один факт для описания разницы между CPU и GPU, я сказал бы так: регистровый файл GPU больше, чем кэш! Давайте возьмем пример RTX 2060 от Nvidia. На каждый SM есть регистр размером 256 КБ, в то время как L1 / разделяемая память для этого конкретного SM составляет всего 96 КБ.
Скрытие задержки (Latency)
Зная, насколько велики регистры GPU, мы теперь можем понять, почему графические процессоры настолько эффективны при обработке большого количества данных. Большая часть работы выполняется одновременно. Даже когда всего один поток в подгруппе должен чего-то ждать (например, выборки из памяти), графический процессор не ждет. Вся подгруппа отмечается как остановленная. Выполняется другая подходящая подгруппа из пула подгрупп, хранящихся в регистрах. Как только завершается предыдущая операция, которая послужила причиной задержки, подгруппа запускается для завершения работы над ней снова. И в реальных сценариях это происходит с тысячами подгрупп. Возможность немедленно переключиться на другую подгруппу, если возникла задержка, имеет решающее значение для графического процессора. Он скрывает время ожидания, запуская другой набор подходящих подгрупп.
Немного матчасти:
- active Subgroup, активная подгруппа — та, которая выполняется
- resident Subgroup/Subgroup in flight, резидентная подгруппа / подгруппа в полете — хранится в регистрах
- eligible Subgroup, подходящая подгруппа — она хранится в регистрах и помечается как готовая к запуску или повторному запуску
Занятость (Occupancy)
Краткая версия: соотношение, насколько хорошо заполнен GPU.
Занятость — это не про то, насколько хорошо мы используем графический процессор! Это количество резидентных подгрупп (возможность скрыть задержку). ALU могут испытывать максимальную нагрузку даже при низкой занятости, хотя в этом случае быстро теряется производительность использования.
Расширенная версия: предположим, что некий вычислительный блок может иметь 32 резидентных подгруппы (полная емкость регистрового файла). Теперь давайте отправим 32 полностью независимых подгруппы с работой, чтобы полностью заполнить его. Даже если 31 из 32 возможных подгрупп остановлена, возможность скрыть задержку все еще есть при выполнении 32-й. Это и есть соотношение: сколько независимых подгрупп отправилось на исполнение из всех возможные подгрупп в полете.
Теперь предположим, что вы отправляете 8 рабочих групп по 128 потоков в каждой (охватывает 4 подгруппы). На этот раз рабочие группы нужно обрабатывать вместе (если группы будут полностью независимыми, драйвер разделит их на 4 отдельные подгруппы, создавая точно такую же ситуацию, как была выше). Другими словами, теперь каждому потоку требуется 4 регистра. Вычислительный блок остается прежним, поэтому в нем все еще есть только 32 возможные подгруппы. Поэтому оказалось в 4 раза меньше возможностей скрыть задержку (переключиться на другие 4 подгруппы), потому что каждая рабочая группа теперь в 4 раза больше. Это означает, что заполняемость составила всего 25%. Здесь важно помнить следующее: увеличение использования регистров для каждой подгруппы снижает общую занятость. Если только данные не структурированы исключительно хорошо, распределение рабочих групп почти никогда не достигает 100% занятости. Экстремальный случай: если вы отправляете одну рабочую группу во весь размер регистра вычислительного блока, тогда при остановке нечего переключать (нет возможности скрыть задержку).
Дефицит регистров и выгрузка регистров
Давайте продолжим предыдущий пример. Что, если каждому потоку нужно еще больше места в регистрах? Каждый раз, когда мы увеличиваем требования к потокам, измеряемые в необходимом пространстве регистров, мы также увеличиваем дефицит регистров (register pressure). При низком дефиците регистров беспокоиться не о чем, мы просто уменьшим занятость (что тоже неплохо, пока всегда есть работа, чтобы скрыть задержку). Но как только мы начнем увеличивать использование регистров на поток, мы неизбежно достигнем уровня, при котором драйвер может принять решение о выгрузке регистров. Выгрузка регистров (register spilling) — это процесс перемещения данных, которые обычно должны храниться в регистрах, в кэш L1/L2 и/или во внешнюю память (память устройства в Vulkan). Драйвер решает сделать это, если занятость действительно низкая, чтобы сохранить часть возможностей для скрытия задержки за счет более медленного доступа к памяти.
Примечание: хотя выгрузка во внутреннюю память устройства может фактически повысить производительность,4 это менее очевидно при выгрузке во внешнюю память.
Скаляры и векторы
В одном из предыдущих абзацев говорилось, что мы не можем выполнять работу меньше, чем размер рабочей группы. На самом деле это еще не все. Аппаратные средства AMD по своей природе векторные. Это означает, что у них есть отдельные блоки для векторных и скалярных операций. Nvidia, с другой стороны, скалярны по своей природе, что означает для подгрупп возможность обрабатывать смешанные типы данных (в основном комбинацию F32 и INT32). Значит, предыдущий абзац был ложью, и мы на самом деле можем выполнять работу меньшую, чем Subgroup? Правильный ответ: мы не можем, а планировщик может. Разделение работы, которую необходимо выполнить, зависит от планировщика. Это не меняет факта, что планировщик по-прежнему будет принимать количество скаляров не менее размера подгруппы, он просто не будет использовать его. В том же сценарии AMD должна использовать весь вектор, но ненужные операции будут обнулены и отброшены.5 Intel пошла еще дальше в этом решении, поскольку размер вектора может различаться!
Предыдущие абзацы остаются в силе. Если вы не выполняете микрооптимизацию разметки данных, которые передаются на графический процессор, разницей можно пренебречь. Подход AMD должен давать действительно хорошие результаты, если данные хорошо структурированы. Для получения большего количества случайных данных, скорее всего, лидирует Nvidia.
Использование не родственных типов данных
Здесь мы имеем два случая:
- Использование типов, превышающих стандартный собственный размер
- Использование типов меньше обычного собственного размера
Большинство графических процессоров потребительского класса используют 32 бита с плавающей точкой как наиболее распространенный собственный размер. Что же произойдет, если мы будем использовать число двойной точности с плавающей точкой (64 бит)? Если одновременно будет отправлено не слишком много, не произойдет ничего ужаснее, чем максимальное использование регистров (регистры в графических процессорах используют 32-битные элементы, поэтому 64-битные числа с плавающей точкой занимают два из них). Большинство производителей графики предоставляют отдельные блоки F64 или блоки специального назначения для обеспечения более точных операций.
Интересней использование меньших чем исходные размеров. Во-первых, у нас действительно есть оборудование, которое может с этим справиться (по крайней мере, в настоящее время). Числа вдвое меньшей точности с плавающей точкой пользуются большим спросом вот уже несколько лет. Не только из-за машинного обучения, но и для конкретных игровых целей. Turing здесь очень интересная архитектура, поскольку она разделяет графические процессоры на варианты GTX и RTX. У первого нет ядер RT и тензорных ядер, а у второго есть и то, и другое. Тензоры RTX — это специальные блоки FP16, которые также могут обрабатывать типы INT8 или INT4. Они специализируются на матричных операциях FMA (Fused Multiply and Add). Основная цель тензорных ядер — использовать DLSS,6 но я слепо предполагаю, что драйвер может принимать решение использовать их и для других операций. Версия архитектуры Тьюринга GTX (1660, 1650) не имеет тензорных ядер, вместо этого у нее есть свободно доступные блоки FP16! Они больше не специализируются на матричных операциях, но планировщик может использовать их по своему усмотрению, если это необходимо.
16-битные числа с плавающей точкой также известны как числа половинной точности.
Что произойдет, если мы используем F16 на графическом процессоре, у которого нет аппаратного эквивалента, ни в ядре Tensor, ни в отдельных модулях FP16? Мы по-прежнему используем блоки FP32 для обработки, и что более важно, мы потратим впустую регистровое пространство, потому что независимо от размера числа мы все равно помещаем его в 32-битный элемент. Но есть одно большое улучшение: нужна меньшая пропускная способность.
Ветвление плохо, верно?
Вы могли слышать это много раз, но правильный ответ — зависит от обстоятельств. Когда кто-то отрицательно говорит о ветвлении, имеют в виду, что это происходит внутри подгруппы. Другими словами, ветвление внутри подгруппы — это плохо! Но это лишь половина дела. Представьте, что вы используете графический процессор Nvidia и отправляете 64 потока работы. Если 32 последовательных потока заканчиваются одним путем, а остальные 32 — другим, то ветвление нормально. Другими словами, совершенно нормально ветвление между подгруппами. Но если будет ветвиться только один поток из 32 упакованных чисел с плавающей точкой, тогда другой будет его ждать (помечен как неактивный), и мы закончим ветвлением внутри подгруппы.
Кэш L1, LDS и общая память
В зависимости от принятого названия вы можете увидеть LDS (локальное хранилище данных) и разделяемую память, на самом деле они оба обозначают одно и то же. LDS — это название, используемое AMD, а Shared Memory — термин, введенный Nvidia.
L1$ и LDS/Shared Memory — разные вещи, но обе они занимают одинаковое пространство на оборудовании. У нас нет явного контроля над использованием кэша L1. Всем этим управляет драйвер. Единственное, что мы можем запрограммировать, — это локальное хранилище данных, которое разделяет пространство с кэшем L1 (с настраиваемыми пропорциями). Как только мы начнем использовать разделяемую память, у нас могут возникнуть некоторые проблемы …
Конфликты банков памяти
Разделяемая память разделена на банки. Вы можете думать о банках как о ортогональных вашим данным. То, как каждый банк отображается для доступа к памяти, зависит от количества банков и размера слова. Возьмем для примера 32 банка с 4-байтовым словом. Если у вас есть массив из 64 чисел с плавающей точкой, тогда только 0-й и 32-й элементы будут заканчиваться в bank1, 1-й и 33-й будут заканчиваться в bank2 и т.д. Теперь, если каждый поток из подгруппы обращается к уникальному банку, это идеальный сценарий, поскольку мы можем сделать это за одну инструкцию загрузки. Конфликт банков возникает, если 2 или более потоков запрашивают разные данные из одного банка памяти. Это означает необходимость сериализировать доступ к ячейкам данных, что является чистым злом. В худшем случае вы можете закончить тем, что все потоки будут обращаться к одному банку памяти, но получат 32 разных значения, что фактически означает затрату времени в 32 раза больше.7
Доступ к определенному значению из одного и того же банка многими потоками не является проблемой. Давайте доведем до крайности: если все потоки обращаются к 1 значению в 1 банке, это называется broadcasting — внутри системы выполняется только одно чтение из общей памяти, и это значение транслируется во все потоки. Если некоторые (но не все) потоки обращаются к 1 значению из определенного банка, то у нас multicast.
Немного примеров:
- Оптимальный доступ к разделяемой памяти:
// равномерно распределенный
arr[gl_GlobalInvocationID.x];
//не распределенный равномерно, но каждый поток имеет доступ к разным банкам
arr[gl_GlobalInvocationID.x * 3];- Конфликт банков:
//конфликт "дублирования"
// - при умножении на 2
// - при использовании чисел удвоенной точности
// - при использовании структур из 2 чисел с плавающей точкой
arr[gl_GlobalInvocationID.x * 2];- Broadcast:
arr[12]; //с константами
arr[gl_SubgroupID] //с переменнымиИз-за сокрытия задержки и скорости разделенной памяти конфликты банков могут фактически не иметь значения. Пока одна подгруппа не обнаружит конфликтующий доступ, планировщик может переключиться на другую.
Конфликты банков могут возникать только внутри подгрупп! Нет такой вещи как конфликты банков между подгруппами.
Также может произойти регистровый конфликт между банками.
Компиляция шейдерного процесса напоминает… Java
Современные API, такие как Vulkan и DX12, позволяют избавить компиляцию шейдеров от запуска графического / вычислительного приложения. Мы заранее компилируем GLSL / HLSL в SPIR-V и сохраняем его как промежуточное представление (байт-код) лишь для дальнейшего использования драйвером. Но драйвер берет его (возможно, с изменениями в последнюю минуту, например, с уточнением констант) и компилирует еще раз для кода конкретного производителя и/или оборудования. По сути это очень похоже на действия с управляемыми языками C# или Java, когда компилируется код для IL, который затем компилируется / интерпретируется CLR или JVM на конкретном оборудовании.
Архитектура набора команд (ISA)
Если углубиться в тему, как GPU выполняет наборы команд, то это действительно отличное чтение. Есть две компании, которые свободно делятся ISA для своего конкретного оборудования:
Бонус — названия драйверов у производителей для Linux
Моя основная ОС уже более 6 лет — это Linux. Как всегда, ситуация с драйверами может удивить многих пришедших из Windows, поэтому давайте погрузимся в сложную политическую ситуацию с драйверами Vulkan.
Для Nvidia у нас есть 2 варианта:
- nouveau — можно использовать для обычной повседневной работы, такой как офис или просмотр YouTube, но не для игр и вычислений. Разработка затрудняется некоторыми решениями Nvidia.
- Проприетарный драйвер Nvidia — в большинстве случаев работает безупречно, но без доступа к коду.
AMD:
- AMDVLK — версия с открытым исходным кодом.
- Mesa 3D — библиотека драйверов, которая предоставляет драйвер с открытым исходным кодом (в основном копию AMD-VLK). Самый популярный выбор, когда дело доходит до AMD.
- AMD проприетарный AMDGPU-PRO.
Intel:
- Mesa 3D — как у AMD, драйвер с открытым кодом и часть библиотеки.
Примечания
- RT Core на самом деле занимается обходом BVH, тестом пересечения прямоугольников, тестом пересечения треугольников, и в отличие от всех других шаблонов исполнения в GPU, которые похожи на SIMD, ядро RT имеет тип MIMD.
- Новые архитектуры, например, Turing, могут иметь отдельные исполнительные ядра для int32.
- Такая гибкость приводит к очень интересному преимуществу над AMD и Nvidia.
- Если разделяемая память / кэши L1 или L2 недостаточно инициализированы.
- AMD обычно компенсирует этот архитектурный выбор за счет регистров и кэшей большего размера.
- Суперсэмплинг глубокого обучения может ввести в заблуждение. Хотя вы можете использовать тензорные ядра для глубокого обучения, то, что происходит во время запущенной игры, просто выводится из уже сгенерированных данных. Эти данные вычисляются не на графическом процессоре, а скорее внутри связки подключенных мощных ускорителей Nvidia, и затем сохраняются в блобах драйверов.
- Эту ситуацию можно смягчить, если у каждого планировщика будет много модулей LD / ST, которые могут отправлять более 1 инструкции за цикл (чем больше, тем лучше).

Спасибо, залипательно.