Командный процессор. Путешествие по графическому конвейеру. Часть 2

Вторая часть серии статей про графический конвейер, написанной Фабианом Гизеном и известной под названием «Путешествие по графическому конвейеру 2011».
Не так быстро
В предыдущей части я рассказал про различные места, которые проходят в компьютере ваши команды 3D визуализации прежде, чем они на самом деле передаются в GPU. И это короткая версия, путь длиннее, чем вы думаете. Потом я закончил тем, что назвал командный процессор и описал, что он на самом деле делает с командными буферами. Ну, могу признаться — я солгал вам. На самом деле мы встретимся с командным процессором впервые в этой статье, но помните: все содержимое буфера команд идет через память, либо системную память через PCI Express, либо через локальную видеопамять. Прежде, чем мы доберемся до командного процессора, давайте еще поговорим о памяти.
Подсистема памяти
Подсистема памяти GPU отличается от таковой у процессора или другого «железа», потому что модель работы графических процессоров иная. Существует два основных отличия:
Первое: подсистема памяти GPU быстрая. Серьезно быстрая. Процессор i7 2600К достигнет, может быть, 19 ГБ/с (в самых благоприятных условиях). Видеокарта GeForce GTX 480 имеет общую пропускную способность памяти около 180 Гбит/с — разница почти на порядок! Ого.
Второе: подсистема памяти GPU медленная. Серьезно медленная. Промах кэша в основную память на Nehalem (первое поколение Core i7) занимает около 140 циклов, если умножить на тактовую частоту приведенную AnandTech латентность памяти. GeForce GTX 480, которую я уже упоминал ранее, имеет латентность доступа к памяти 400-800 тактов. Так что давайте просто скажем, что в циклах видеокарта GeForce 480 GTX имеет латентность памяти вчетверо больше, чем Core i7. Кроме того, что вышеупомянутый Core i7 имеет тактовую частоту 2,93 ГГц, в то время как у GTX 480 частота шейдерного блока составляет 1,4 ГГц — еще двухкратная разница. Всего опять-таки, разница величин почти на порядок! Мой здравый смысл подводит меня?
Нет, GPU получает значительное увеличение пропускной способности, но платит за это серьезным увеличением латентности (и как оказывается, серьезным увеличением потребляемой мощности, но это уже выходит за рамки данной статьи). Такова часть общей картины: низкая латентность характерна для памяти GPU.
Это почти все, что вам нужно знать о GPU памяти, за исключением одного кусочка об обычной DRAM, который будет важен в дальнейшем: она логически и физически организована в виде двумерной сетки. Существуют (горизонтальные) строки и (вертикальные) столбцы с ячейками памяти. На каждом пересечении этих линий — транзистор и конденсатор; если в этом месте вы захотите узнать, как в реальности из этих элементов строится память, вам поможет Википедия.
В любом случае, важным моментом относительно адреса в DRAM является то, что он разбивается на адрес строки и адрес столбца. Чтение/запись в DRAM всегда происходит путем доступа ко всем столбцам в данной строке одновременно. Это означает, что намного дешевле открыть память, которая располагается в точности в одной строке DRAM, а не разбросана по нескольким строкам. Сейчас может показаться, что это просто мелкий факт о DRAM, но он станет важным позднее. Отмечу еще, что вы не можете достичь максимальных скоростей шины при чтении нескольких битов там и тут, для этого вам надо считывать всю строку.
Хост-интерфейс PCIe
Это «железо» не представляет интереса с точки зрения графического программиста. Собственно, то же наверно касается аппаратной архитектуры GPU. О нем необходимо помнить как об узком месте по скорости пропускной способности. Кроме этого, он предоставляет процессору доступ на чтение/запись в видео память и кучу регистров GPU, графическому процессору — (частичный) доступ на чтение/запись в основной памяти, и всем — головную боль из-за латентности для всех этих операций еще большей, чем латентность памяти, потому что сигналы должны каким-то образом приспосабливаться к разнице в скоростях между CPU/GPU. (Пиковая) пропускная способность приличная — до 8 Гб/с (теоретически). Это пропускная способность 16-канального PCIe 2.0, с которым сейчас работает большинство процессоров. И половина/треть совокупной скорости процессорной шины — приемлемый коэффициент. В отличие от предыдущих стандартов типа AGP, это симметричное соединение конец к концу в обоих направлениях. У AGP был быстрый канал из CPU в GPU, но не наоборот.
Финальные заметки о памяти
Честно говоря, мы уже очень скоро увидим 3D команды! Так близко, что можем их потрогать. Но сначала нам нужно сделать еще одно отступление. Потому что теперь у нас есть два вида памяти: (местная) видеопамять и подключенная системная память. Какую дорогу мы выберем?
Самое простое решение: Просто добавьте дополнительную адресную строку, которая скажет вам, куда идти. Это просто, работает отлично и делалось много раз. Или вы можете унифицировать архитектуру памяти, как в некоторых игровых консолях (но не ПК). В этом случае выбора нет, есть только память, вместе с которой вы идете. Если вы хотите более продвинутое решение, можно добавить MMU (блок управления памятью), который дает вам полностью виртуализированное адресное пространство и некоторые другие разделы в системе памяти, и позволяет проводить замечательные трюки вроде получения в видеопамять часто запрашиваемых частей текстуры (а это значительное увеличение скорости). Большая часть памяти совершенно не размечена, она собирается как результат чтения диска, и работа проходит крайне неспешно.
Итак, MMU. Она также позволяет дефрагментировать адресное пространство видеопамяти без реального копирования, когда памяти начинает не хватать. Это хорошая вещь. И она значительно облегчает разделение доступа к GPU для нескольких процессов. В любом случае, MMU / виртуальная память — это не совсем то, что вы можете просто приставить сбоку (точно не в архитектуре с кэшами и заботой о согласованности), но на самом деле это не вносит какие-либо особенности ни в один из этапов прохождения конвейера, которые я тут описываю.
Есть также устройство DMA, которое может копировать память не привлекая наши ценные 3D аппаратные / шейдерные ядра. Обычно это может быть копирование между системной и видео памятью (в обоих направлениях). Также можно копировать из видеопамяти в видеопамять (полезно, если нужно сделать дефрагментацию видеопамяти). Копирование между участками системной памяти обычно невозможно, потому что это GPU, а не устройство копирования памяти. Делайте копии системной памяти в CPU, где им не нужно проходить по шине PCIe в обоих направлениях!
Обновление: Я нарисовал картинку. Она показывает больше подробностей, теперь GPU имеет несколько контроллеров памяти, каждый из которых контролирует несколько банков памяти, с жирным хабом перед ними. Все что нужно, чтобы достичь такой пропускной способности. :)
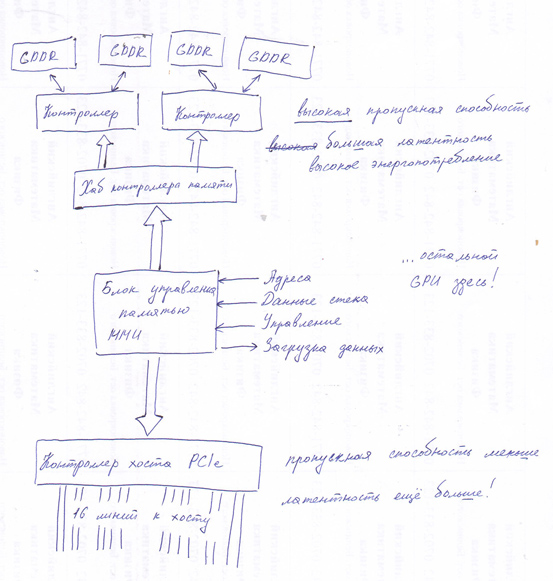
Окей, по пунктам. У нас есть командный буфер, подготовленный процессором. У нас есть хост-интерфейс PCIe, так что процессор может рассказать нам о буфере и записать его адрес в какой-то регистр. Логично превратить этот адрес в нагрузку, которая действительно вернет данные. Если он из системной памяти, он проходит через PCIe. Если мы предпочли взять буфер команд в видеопамяти, KMD может выполнить передачу через DMA, поэтому ни центральный процессор, ни шейдерные ядра на графическом процессоре не должны активно беспокоиться об этом. А затем мы можем получить данные из нашей копии в видеопамяти через подсистему памяти. Все пути рассмотрены, и мы, наконец, готовы увидеть команды!
Командный процессор
Наше обсуждение командного процессора начнется, как многие вещи сегодня, с одного слова:
«Буферизация…»
Как уже упоминалось выше, обе тропинки памяти ведут с высокой пропускной способностью и большой задержкой. Для самых запоздалых битов в конвейере графического процессора решением было идти в несколько потоков. Но в данном случае мы имеем только один командный процессор, который должен пройти командный буфер по порядку (поскольку командный буфер содержит такие вещи, как команды изменения состояния и рендеринга, которые должны быть выполнены в правильной последовательности). Поэтому мы сделаем следующее: добавим достаточно большой буфер с достаточно большой предварительной выборкой, чтобы предотвратить задержки.
Из этого буфера все отправляется на настоящий внешний интерфейс обработки команд, который представляет собой машину состояний, умеющую парсить команды (в соответствующем «железу» формате). Некоторые команды относятся к операциям 2D рендеринга, если нет отдельного командного процессора для 2D-материалов. Да-да, в GPU до сих пор запрятаны 2D аппаратные средства. Например, там находится чип VGA, который поддерживает сохранившийся до сих пор текстовый режим, режим 4-регистровой битовой плоскости, плавный скроллинг и все такое. Дальше — команды, которые на самом деле передают примитивы в 3D/шейдерный конвейер, ура! Я расскажу о них в следующих частях. Есть также команды, которые приходят в 3D/шейдерный конвейер, но никогда ничего не визуализируют по разным причинам (и в различных конфигурациях конвейера). Но про это еще позже.
Еще есть команды, которые изменяют состояние. Как программист, вы представляете их как просто изменение переменной — примерно так и есть. Но GPU — это своего рода параллельный компьютер, и вы не можете просто изменить глобальную переменную в параллельной системе и надеяться, что все работает. Это ошибка, которая рано или поздно проявит себя. Существует несколько популярных методов, все чипы используют разные методы для разных типов состояний.
- Когда вы меняете состояние, требуется закончить все отложенные работы, на которые возможны ссылки (т.е. попросту получается частичная приостановка конвейера). Раньше графические чипы поступали в основном именно так. Увы, количество пакетов и треугольников выросло, а конвейеры стали длиннее. Эта система еще жива и занимается вещами, которые редко меняются (десяток частичных приостановок не столь значим по сравнению с полным кадром) или слишком трудны/дороги в выполнении продвинутыми способами.
- Вы можете сделать аппаратные блоки совсем без состояний. Просто передайте команду изменения состояния до стадии, к которой она относится; потом эта стадия добавляет текущее состояние ко всему, что он отправляет дальше по конвейеру, каждый цикл. Он не хранится нигде, но всегда рядом, поэтому если какой-то этап конвейера хочет посмотреть несколько бит состояния, он может это сделать, потому что они передаются ему (и затем идут дальше). Если ваше состояние длиной всего лишь несколько бит, это довольно дешево и практично. Если это полный набор активных текстур и состояние выборки текстуры — то не так уж.
- Иногда, чтобы немного ускорить интерфейс настройки состояний, хранится и каждый раз затирается только одна копия состояния. Но было бы гораздо лучше хранить две (или четыре?) копии, что интерфейс установки состояний имел некоторую предварительную выборку. Скажем, у вас есть достаточно регистров («слотов») для хранения двух версий каждого состояния, и некий слот 0 со ссылками текущих работ. Вы можете безопасно изменить слот 1, не останавливая текущую работу или каким-либо иным образом вмешиваясь в нее. Теперь вам не нужно отправлять все состояние через конвейер — только один бит на команду, которая выбирает: использовать слот 0 или 1. Конечно, если оба слота 0 и 1 заняты к тому времени, когда приходит команда изменения состояния, вам все равно придется ждать, но вы все-таки двигаетесь на шаг вперед. Тот же метод работает с более чем двумя слотами.
- Для вещей вроде сэмплера или текстуры Shader Resource View возможна одновременная установка большого количества состояний, но шансы на это невелики. Вам не надо резервировать пространство состояний для 2 * 128 активных текстур только потому, что вы отслеживаете 2 набора текущих. Для таких случаев вы можете использовать что-то вроде схемы переименования регистров: надо иметь пул из 128 физических дескрипторов текстур. Если кому-то действительно понадобится 128 текстур в шейдере, то изменение состояний будет мееедленным. (Непруха). Но чаще всего приложения используют не более 20 текстур, поэтому у вас есть чуть-чуть свободного места, чтобы хранить несколько версий.
Это не полный список, но суть в том, простые на вид вещи типа изменения переменной в вашем приложении (и даже в UMD/KMD и буфере команд!) может в действительности нуждаться в немалом объеме вспомогательного «железа».
Синхронизация
Наконец, последнее семейство команд имеет дело с CPU/GPU и GPU/CPU синхронизацией.
Как правило, все это имеет форму «если происходит событие X, делать Y». Я разберусь с частью программы «делать Y» сначала. Есть два разумных варианта, чем может быть Y: первое, это пуш-образные уведомления, где GPU заставляет CPU делать что-то сразу («Эй! CPU! Я сейчас делаю кадровый гасящий импульс на дисплее 0, поэтому если ты хочешь переключить буферы без разрыва, сейчас самое время!») или это может быть противоположная модель, где GPU просто запоминает, что что-то произошло, и CPU может позже спросить об этом («Ответьте, GPU, какой был самый последний фрагмент командного буфера, который вы начали обрабатывать?» — «Позвольте мне проверить … порядковый номер 303»). Первое обычно реализуется с помощью прерываний и используется только для нечастых и высокоприоритетных событий, потому что прерывания довольно дороги. Все, что нужно для второго — видимые процессором регистры GPU и способ записи в них значений из буфера команд, когда происходит определенное событие.
Скажем, у вас есть 16 таких регистров. Затем можно установить currentCommandBufferSeqId в регистр 0. Вы устанавливаете порядковый номер каждого командного буфера для отправки в GPU (это в KMD), а затем в начале каждого буфера команд добавляете «Если ты доберешься до этой точки в буфере команд, запиши в регистр 0». И вуаля, теперь мы знаем, какой буфер команд GPU сейчас пережевывает! Мы знаем, что командный процессор завершает команды строго по порядку. Когда он обработал команды в буфере 303, это означает, что все командные буферы до 302 включительно обработаны и могут быть возвращены KMD, освобождены, изменены и что он там еще собирался с ними делать.
Теперь у нас также есть пример, чем может быть X: «Если ты здесь» — пожалуй, самый простой пример, но уже пригодный. Другие примеры. «Если все шейдеры завершили все просмотры текстур, поступающие из пакетов до этой точки в командном буфере (это означает безопасные точки для возвращения памяти, задействованной под текстуры / цели рендеринга)». «Если закончен рендеринг всех активных целей / представления неупорядоченного доступа завершены» (это отмечает точки, в которых вы фактически можете использовать их в качестве текстур). «Если все операции до этого момента полностью завершены» и так далее.
Такие операции обычно называются «барьерами», кстати. Есть разные методы подбора значений для записи в регистры статуса, но насколько я могу судить, единственный разумный способ сделать это — использовать последовательный счетчик (возможно, припрятывая некоторые биты для другой информации). Да, я просто привожу это здесь без каких-либо объяснений, потому как считаю, что вы должны знать. Я мог бы рассказать об этом в другом посте (хоть и не в этой серии :) :).
Итак, половина у нас есть — теперь мы можем отчитаться о состоянии GPU перед CPU, что позволяет нам сделать вменяемое управление памятью в драйверах (в частности, мы можем теперь узнать, когда безопасно вернуть память, использованную для буферов вершин, командных буферов, текстур и прочих ресурсов). Но это еще не все — у головоломки есть недостающая часть. Что, если нам нужно синхронизировать исключительно на стороне GPU, например?
Давайте вернемся к однобуферному примеру. Мы не можем использовать что-либо в качестве текстуры до тех пор, пока рендеринг фактически не закончен (и некоторые другие действия имели место, но мы еще будем говорить про блоки обработки текстур). Решение в стиле команды ожидания: «Подождать, пока регистр M содержит значение N». Можно использовать операторы равенства или меньше (обратите внимание, здесь вы должны иметь дело с циклическим возвратом!). Я использую равенство для простоты. Это позволяет нам выполнять синхронизацию, прежде чем мы отправим пакет. Также оно позволяет нам построить полную операцию очистки GPU: «Установить в регистре 0 значение seqId++, если все отложенные задания закончены» / «Подождать, пока регистр 0 содержит seqId». Сделано. GPU/GPU синхронизация — решена. Вплоть до введения на DX11 с вычислительными шейдерами, для которых применяется более тонкая синхронизация, это был единственный механизм синхронизации на стороне GPU. Для простого рендеринга большего и не требуется.
Кстати, если вы можете писать в эти регистры со стороны процессора, вы можете использовать синхронизацию в другую сторону. Отправьте командный буфер (завершения кадра), содержащий ожидание для определенного значения, а затем измените регистр из CPU, а не GPU. Такого рода вещи могут быть использованы для реализации многопоточного рендеринга в стиле D3D11, когда можно отправить пакет, ссылающийся на заблокированные на стороне процессора буферы вершин/индексов (вероятно, они пишутся в другом потоке). Вы просто вставляете ожидание прямо перед фактическим вызовом визуализации. Затем CPU может изменить содержание регистра, как только вершинные/индексные буферы по-настоящему разблокированы.
Если GPU не доходит до этого места в командном буфере, команда ожидания фиктивна; если доходит, то ожидание крутится некоторое время (в командном процессоре), пока не подоспеют данные. Довольно изящно, не так ли? На самом деле, можно реализовать такие вещи даже без CPU-записываемых регистров состояния. Если вы можете изменить командный буфер после того, как отправите его, при условии наличия в командном буфере инструкции jump. Оставляю подробности вам для самостоятельного поиска :)
Конечно, вам не обязательно нужна модель установки регистра / ожидания. Для синхронизации GPU/GPU вы также можете легко выполнить команду «барьера», которая гарантирует безопасность использования цели рендеринга и команду «приостановки конвейера». Но мне больше нравится модель в стиле установки регистров, потому что она убивает двух зайцев (отчетность об используемых ресурсах в CPU и самосинхронизацияGPU) одной хорошо спроектированной пулей.
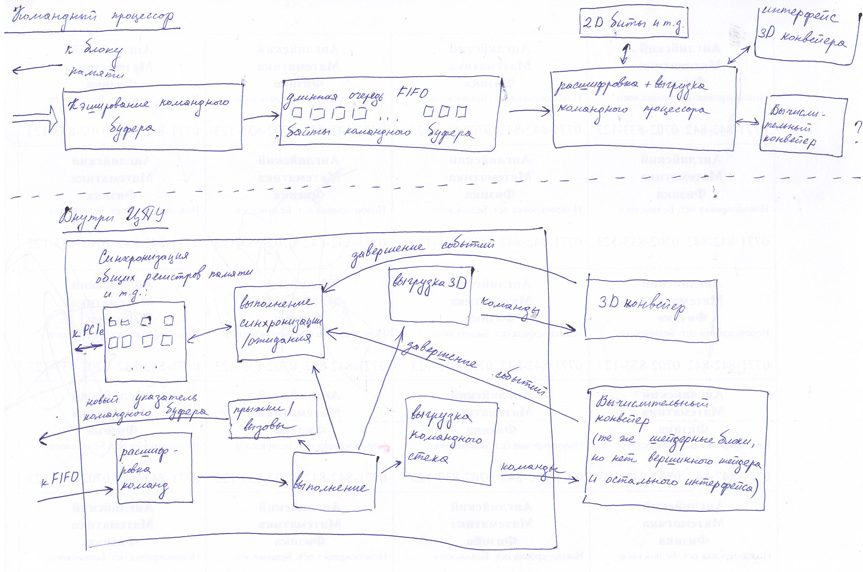
Обновление: Вот, я нарисовал схему для вас. Она немного запутана, так что я собираюсь уменьшить число деталей в будущем. Основная идея заключается в следующем: командный процессор получает вначале директиву FIFO, затем логику расшифровки команды, выполнения осуществляется посредством различных блоков, которые взаимодействуют с 2D устройством, 3D интерфейсом (обычный 3D-рендеринг) или шейдерными блоками напрямую (вычислительными шейдерами). Затем есть блок, который вызывает команды синхронизации/ожидания (он обращается к общедоступным регистрам, о которых я говорил), и один блок, который обрабатывает переходы/вызовы командного буфера (который изменяет текущий вызываемый адрес для FIFO). И мы заставляем все устройства отправить сообщение о событиях завершения. Так что мы знаем, когда, например, текстуры больше не используются, и мы можем высвободить использованную под них память.
Заключительные пометки
На следующем шаге впервые выполняется кое-какая первичная визуализация. Наконец, только в 3 части моей серии о GPU мы на самом деле начинаем рассматривать данные о вершинах! (Нет, треугольники еще не растеризованы). Это займет немного больше времени.
В действительности, на данном этапе конвейера есть развилка: если мы переходим к вычислительным шейдерам, следующим шагом будет… запуск вычислительных шейдеров. Но пока мы идем не туда, потому что вычислительные шейдеры — это тема для следующих частей! Сначала конвейер простого рендеринга.
Небольшая оговорка. Опять же, здесь я рассказываю в общих чертах, вдаваясь в подробности где это нужно (и интересно). Но поверьте мне, я многое отбросил (для удобства и простоты понимания). Я не думаю, что отбросил действительно важное. И, конечно, я мог кое-где ошибиться.
Источник: https://fgiesen.wordpress.com/2011/07/02/a-trip-through-the-graphics-pipeline-2011-part-2/
